Coyote Testing Tool
All about Coyote, the open source tool that automates testing of our data streaming technologies. For more, visit Coyote’s Github repository

Aug 20, 2016

A few days ago we open source’d Coyote, a tool we created in order to automate testing of our data streaming technologies.
Coyote does one simple thing: it takes a .yml file with a list of commands to
setup, run and check their exit code and/or output. It has some other
functionality too, but its essence is this. The source code is short, I don’t
expect any praise for it; coyote is a tool, a useful one.
We use it for environment and operations testing, as well as runtime meta-testing.
Environment and operations testing is to verify that an environment is set up and working as expected, such as having access to a specific port or software, or running a command and getting certain results, like compiling a program that requires tools and libraries present and set-up or a command that needs some environment variables set. Performance testing can also be seen as a subset of environment and operations testing.
Runtime meta-testing is a shortcut to proper software-run-tests. If you trust your software to be robust enough, then instead of verifying the actual results (e.g entries in a database), you can scan the output of the software for (un)expected logs. Of course this kind of tests should not be used without awareness of the underlying dangers.
Coyote has two important outputs; (a) an HTML report with the commands ran, their exit status, stdout, stderr and some statistics, (b) its exit code which up to 254 indicates the number of errors occurred and at 255 is like saturation arithmetic and means that 255 or more errors occurred. The HTML report is for humans and the exit code is for machines. We use it with Jenkins CI where, amongst other things, we need a quick visibility of failures and verbose output for debugging.
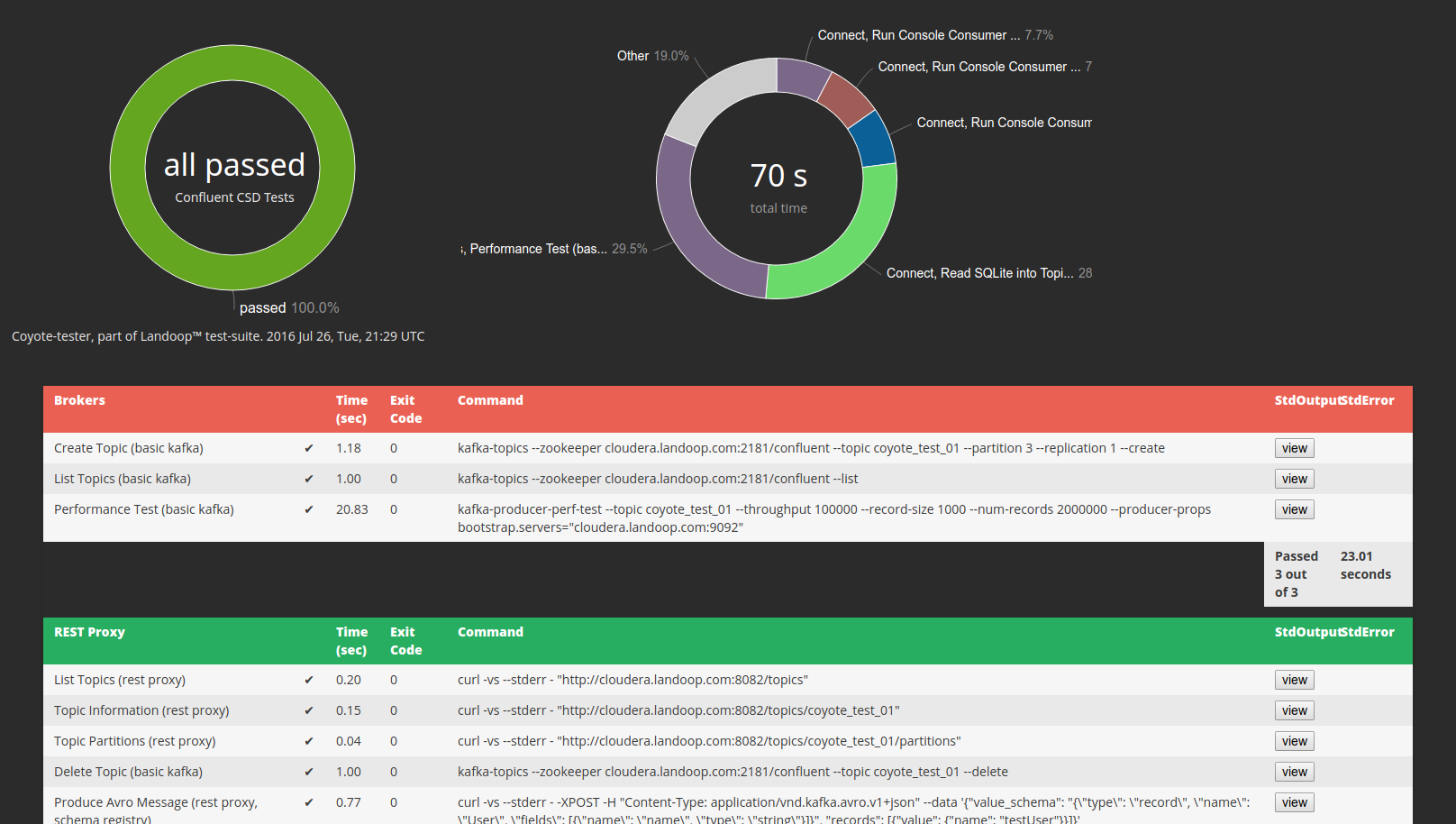
Test configuration is set via a YAML file, partially inspired by Ansible. Let’s see a real world example before we delve into specifics. Below are two of our Box tests, a basic HDFS/Hadoop test and a Spark test. I’ve add some comments to explain what happens for the non-intuitive parts.
In practice you write your tests once or a few times and run them many times. The person running the tests and/or evaluating the results may be not the one that wrote them. Even the creator after a couple months can forget the purpose of each command. In Lenses.io we also use the coyote configuration files as reference examples for both newcomers and ourselves.
Currently coyote supports this settings for each command:
workdir: run the command in this directory
stdin: pass this as standard input to the command
nolog: do not count, nor log this command, usually we use it for small cleanup
tasks
env: array of environment variables to make available to the command
timeout: if the command hasn’t completed in this time, kill it. It takes
Go time duration strings, such as “30s”,”2m15s”,”1h”. There is a global
default timeout of 5 minutes, which you can override globally and/or per command
stdout_has, stdout_not_has, stderr_has, stderr_not_has:
arrays with regular expressions to check against standard output and standard
error.
ignore_exit_code: do not fail the test if exit code is not zero, it still may
fail from a timeout or a stdout/stderr check
skip: if set to true, skip this test (or the group of tests if “skip” is at the
group level), useful for automating test runs by using sed to select tests
Also it supports some special strings:
%UNIQUE%: if this string is used inside a command, stdin, or env variable,
it will be replaced by a unique numeric string at runtime
%UNIQUE_[0-9A-Za-z_-]+%: if such a string (e.g: %UNIQUE_VAR1%, %UNIQUE_1-B%)
is used, all its instances inside commands, stdin and env variables will be
replaced by a common unique numeric string at runtime
Some features you may miss are:
loop constructs (such as Ansible’s “with”)
global variables / templating
abort if a test fails —this is a design choice for now, we always run all
tests
Most of the time it is Jenkins that runs our tests.
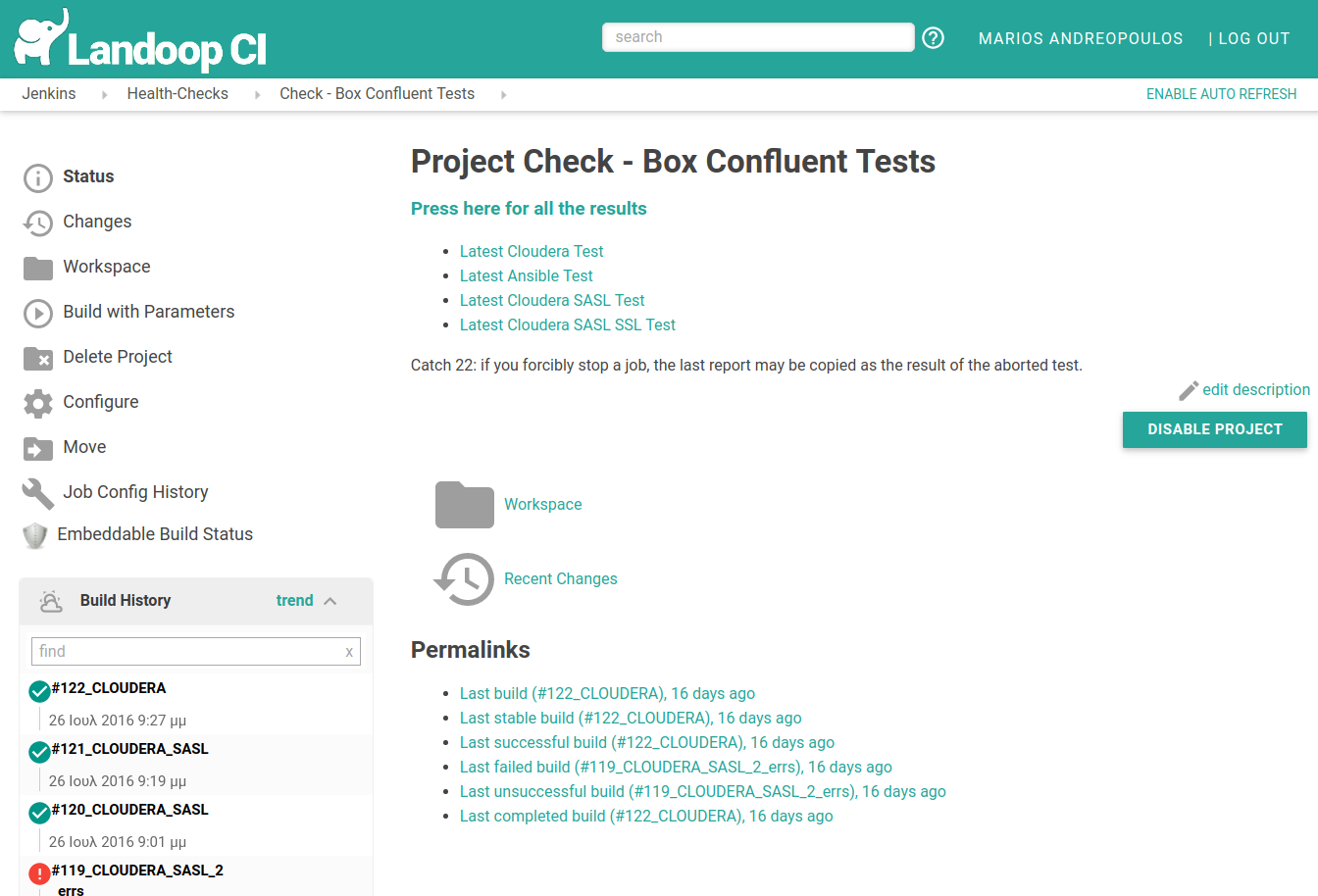
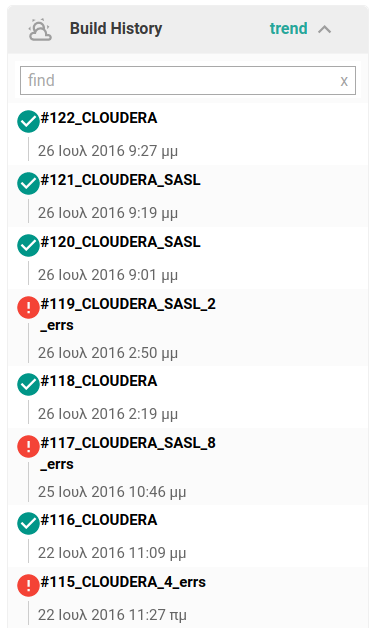
We’ve set it to use Coyote’s exit code not only to mark the build as failed, but to add the number of errors to the job name, to grant us quick visibility of the current status. We also keep a history of test reports.
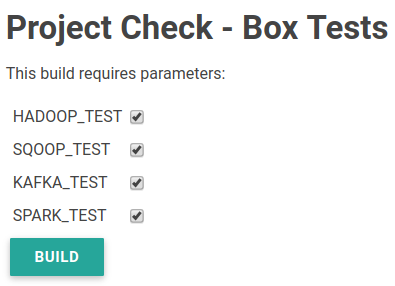
Enabling or disabling tests is easy, add a boolean variable for each test
group and then a single bash line to set its skip flag to true:
Although code testing is such a renowned practice, our research didn’t reveal many testing tools for the latter part of the DevOps pipeline, such as the deployment and execution phase. Coyote’s turnaround has been great until now and this is the reason we wanted to share it.
Of course, as it is with every such effort, we are bound to re-invent the wheel for some part. The codebase is kept small and Go makes it easy to add features as we go.
For the time being we don’t have a release plan, just grab the latest coyote commit from master, it works:
go get github.com/Landoop/coyote
To use it:
coyote -c configuration.yml -out test.html
To make changes to the source code:
Should we make any breaking changes to the configuration format, we will explore how to communicate about it and protect Coyote’s current users.
If you are interested in examples or extending the code, visit Coyote’s Github repository.
Thank you for your time, Marios.
How to write Protobuf-based Kafka producer & consumer microservices wi...
Eleftherios Davros
Mar 01, 2022





