Apache Kafka Streaming, count on Lenses SQL
Lenses SQL is the easiest way to count large scale streams in Apache Kafka. Learn how Lenses allows you to run count aggregations efficiently

Oct 14, 2017

In this brief entry we will discuss how count aggregation can be coded faster with Lenses SQL.
Count aggregations is a very common scenario in stream processing. Some common use cases include aggregated time reports of transaction counts for a payment provider, views of products for an e-commerce site, how many customers are viewing a hotel and many more. In this article we will see how Lenses allows you to run these aggregations leveraging Lenses SQL engine.
Assume a global payments provider is receiving a large amount of multi-currency transactions into a Kafka topic. Understanding their data volume requires access to real time reports counting the number of transactions per minute or currency transactions per 1 minute interval. This empowers the business to react and take relevant actions.
Here is all thats required to do this in Lenses:
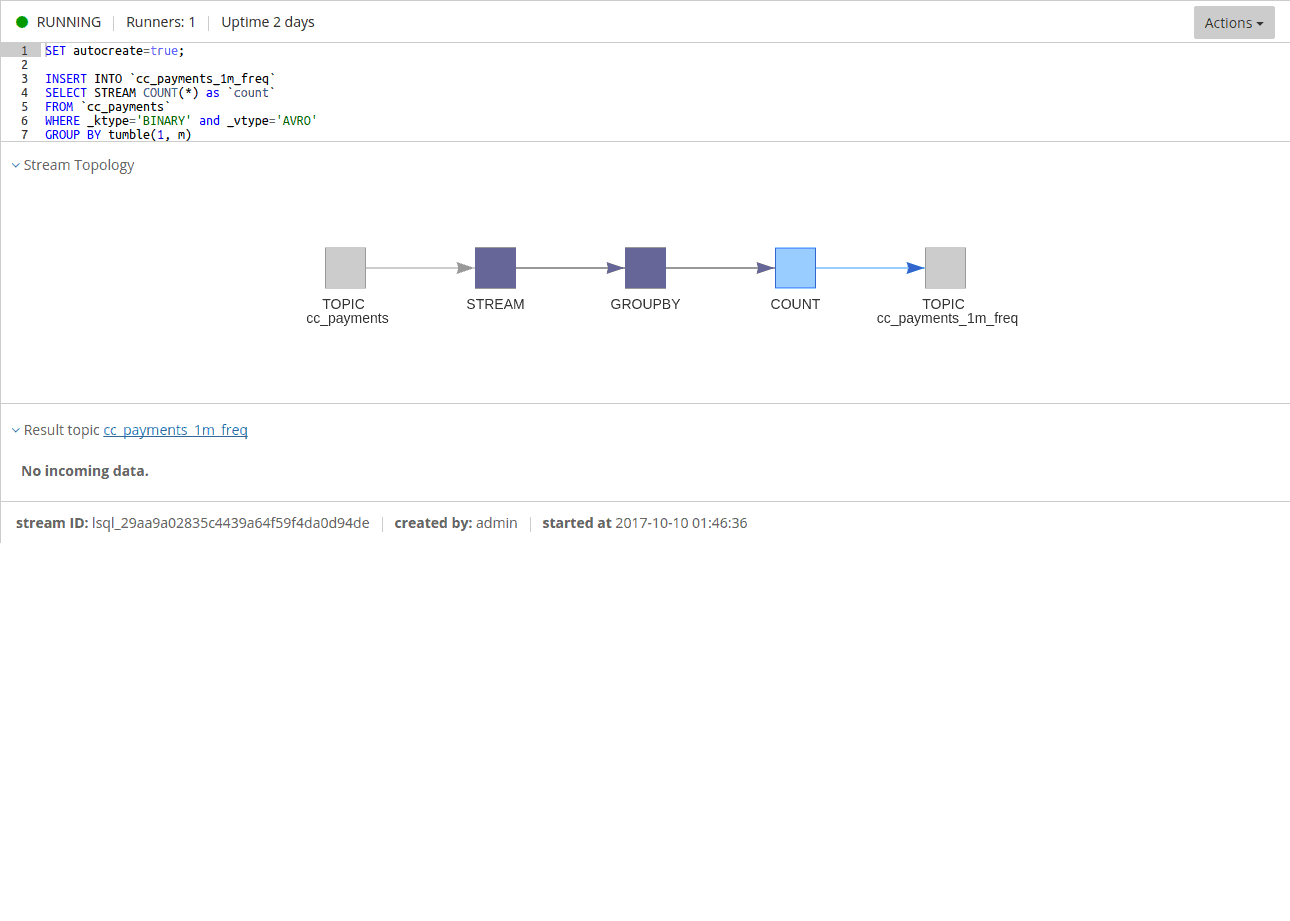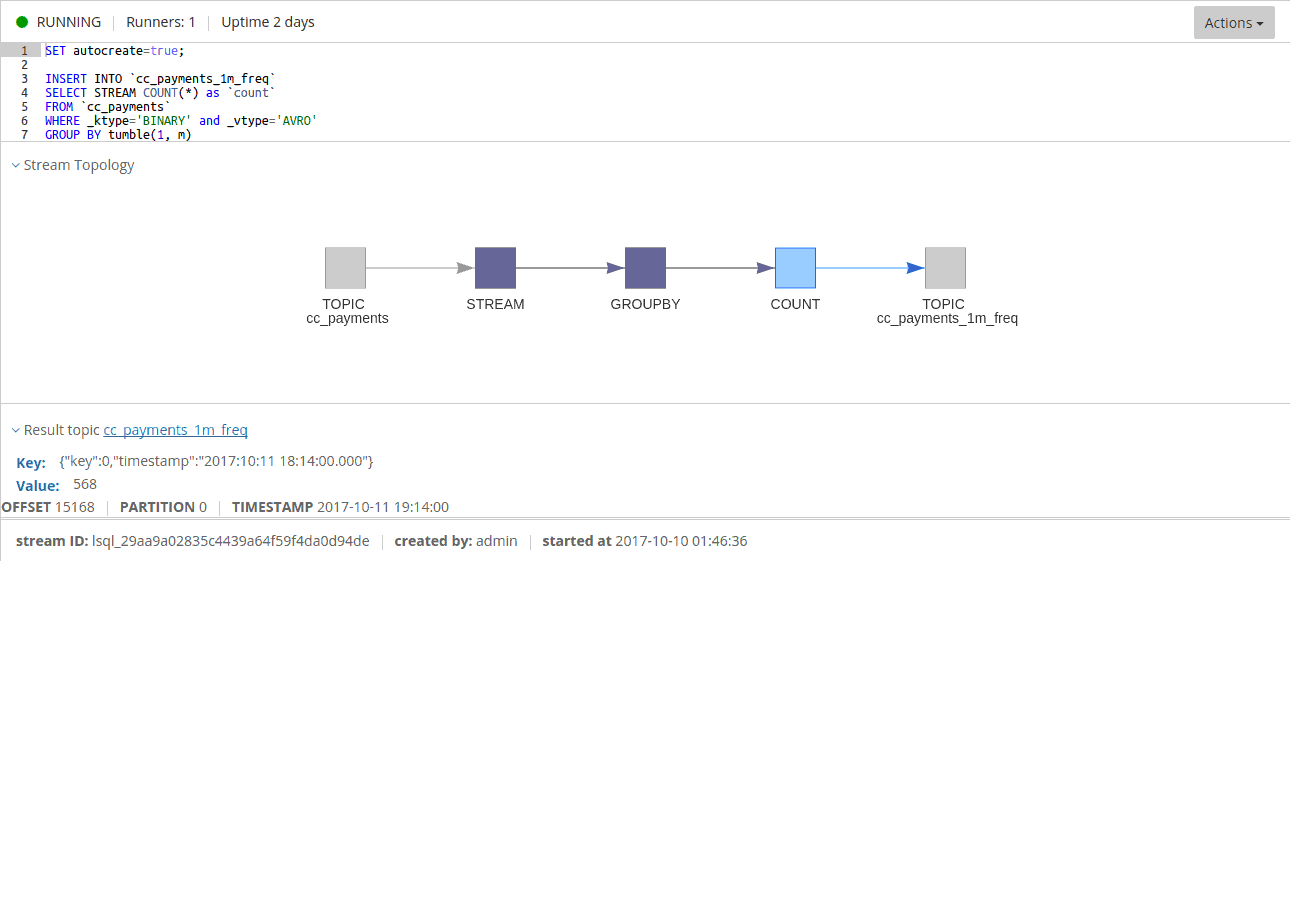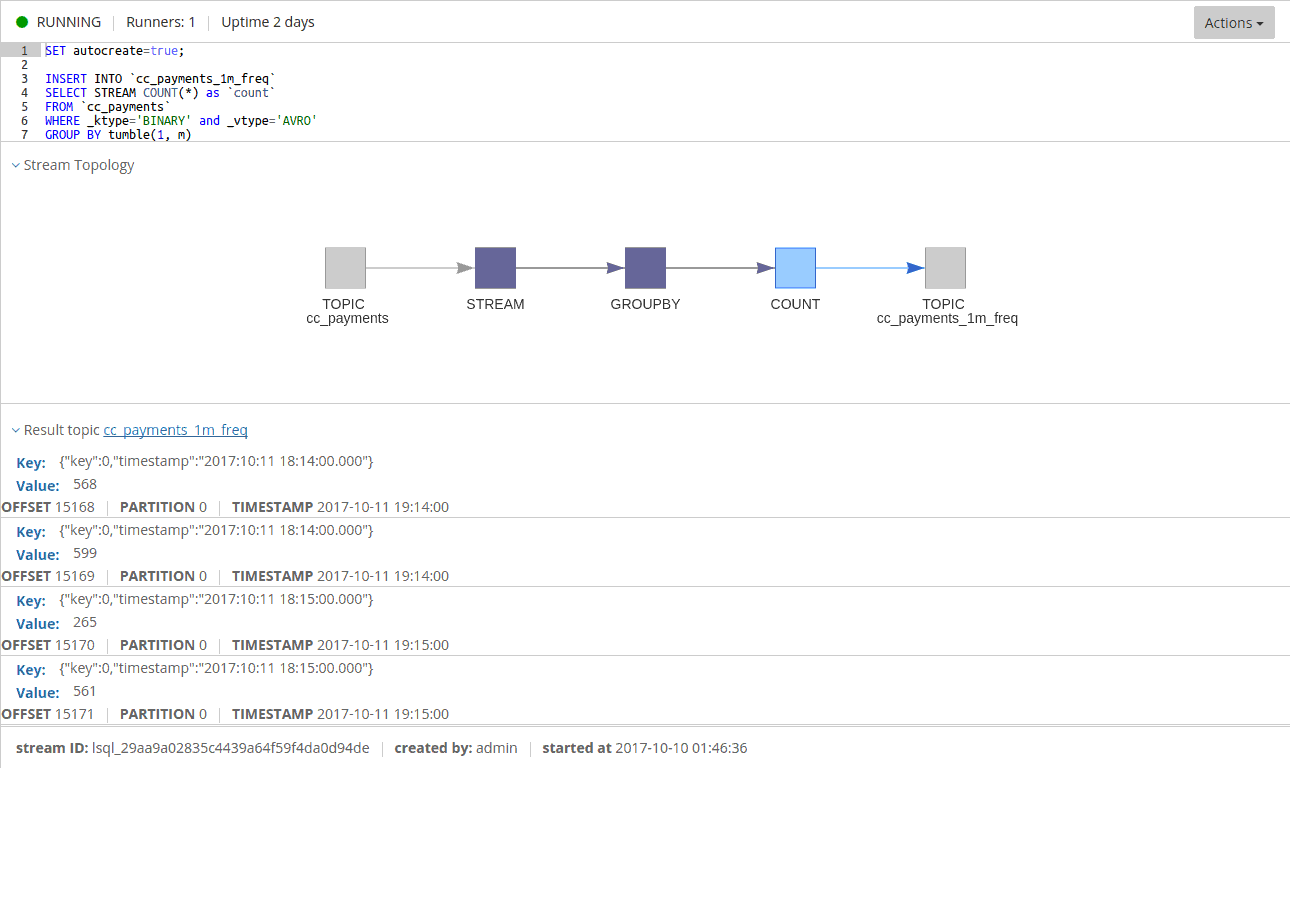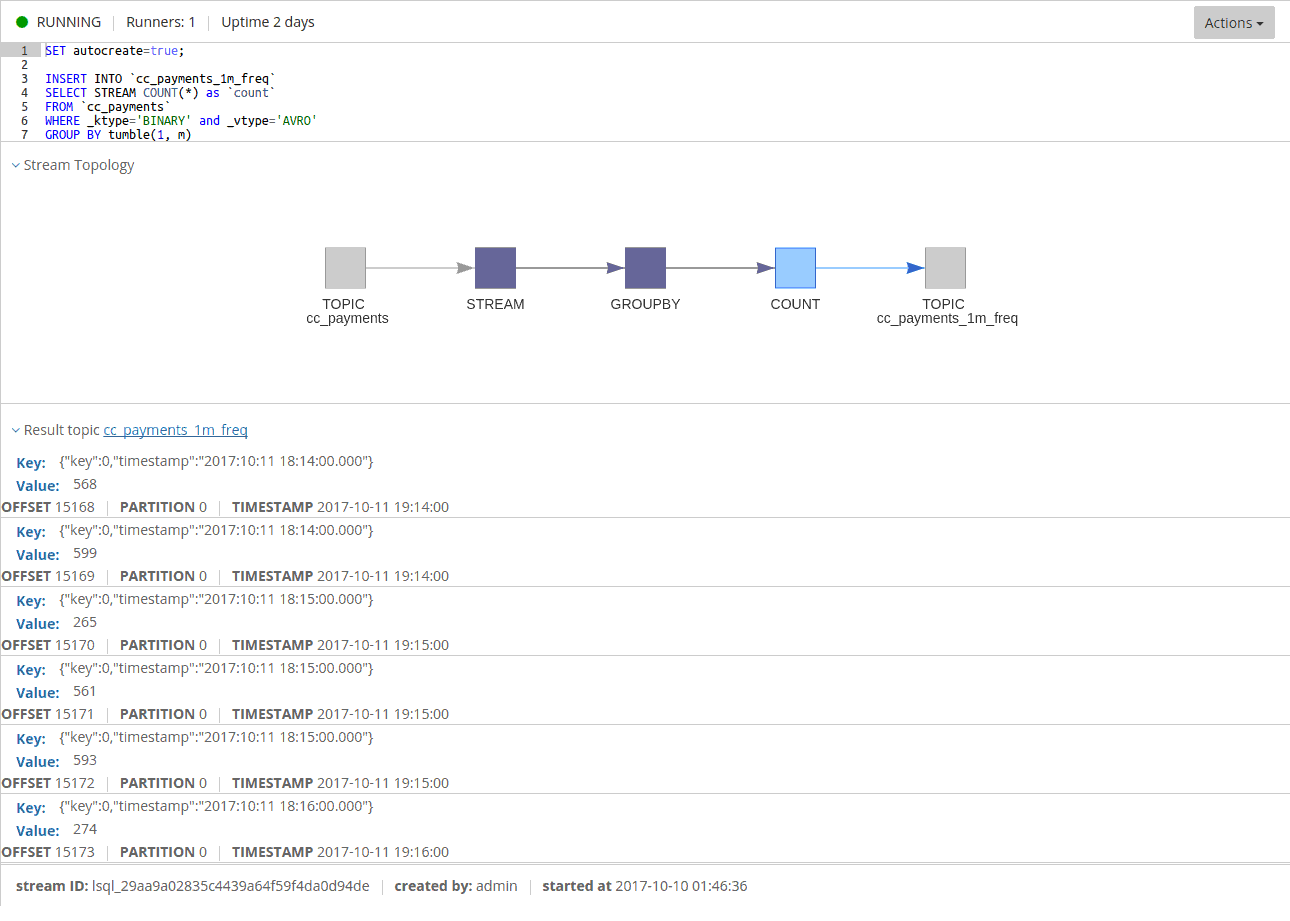
Lenses SQL will translate the code above into a Kafka Streams application while Lenses takes care of execution and scaling.
The first line instructs Lenses SQL engine to autocreate the target topic (cc_payments_1m_freq) if such topic does not exist.
You might have spotted the STREAM keyword. In Lenses SQL this means the query will translate to an instance of KStream.
If you are not familiar with Kafka Streams DSL, a KStream is an abstraction of a record stream, where each data record represents a self-contained datum in the unbounded data set. You should check the Apache Kafka documentation to find more if you need to.
This stateful Kafka stream flow keeps a count for each message sent for a time window of 1 minute. Windowing allows you to control how to group records with the same key for stateful operations (aggregations or joins). In this scenario we have used a tumbling window - this window models fixed-size, non-overlapping, gap-less windows.
Each record received by the stream is an Avro record, hence the code specifies the decoder as _vtype = 'AVRO'.
There is an optimization to be made here since we are not using any of the Avro record field.
To speed up the stream processing we can use the binary decoder for the value part and avoid the Avro deserialization overhead.
The optimized Lenses SQL code is:
Given the code above, we will see entries like this:
You might think there is something wrong with counting the records. However, that is not the case.
The rate of updates depends on your input data rate, the number of parallel running Kafka Streams instances
(see the parallelization setting in Lenses) and the StreamsConfig configuration parameters for commit.interval.ms.
The commit interval is the frequency with which to save the position of the processor in a Kafka stream flow.
Please consult the documentation if not familiar with the terminology. By default is 30 seconds, if exactly-once semantics is not enabled.
This means the processor punctuate method is called every 30 seconds. Maybe you think the solution is to set this value to 60 seconds?
There is a catch here: the processor punctuate interval is not aligned with the timestamp on the records received in the stream.
There is quite a bit of luck involved to have them matching. This means that the resulting value for each window interval will be emitted twice.
To reduce the number of emitted records you can extend the commit interval to be 120 seconds. This is a better solution:
Using the same example of payments, we can easily count the transactions on each 1 minute interval, for each currency involved in the payment request. Here is the Lenses SQL code that allows you to quickly describe and execute such a Kafka stream flow:
In this code sample we read each stream record value as an Avro record. The stream key is remapped to be the currency field present in the incoming Avro,
and then the aggregation is applied using the tumble window specified. The resulting count is written to the cc_payments_1m_ccy_freq topic every 120 seconds.
Easy!
So far, we have seen in this brief article how easy and fast it is to do a count aggregation; all it takes is a Lenses SQL processor being registered.
Lenses SQL Engine and Lenses platform work together to allow you to focus on your business requirements.
Although counting aggregations are relatively easy to implement via code (yes, it requires you to be a Java/Scala/Clojure developer), it won’t be implemented faster than just registering a Lenses SQL processor via a simple web interface and having deployment and scala out functionality provided out of the box.
The key information for you to take away from this blog entry is: Lenses as a platform takes care of deployment, execution, scalability and monitoring of Kafka Streams applications described through Lenses SQL.
If you want to learn more about Lenses SQL and/or Lenses, we would love to schedule a demo for you and your team.
You can contact us @Lensesio or via email info@lenses.io.





