Apache Kafka and GDPR Compliance
Data Protection Regulations

Dec 01, 2017

Read the March 2021 updated guide Architecting Apache Kafka for GDPR compliance.
GDPR is an important piece of legislation designed to strengthen and unify data protection laws for all individuals within the European Union. The regulations becomes effective and enforceable on the 25th May 2018.
Our commitment is to provide the necessary capabilities in data streaming systems, to allow your data-driven business to achieve compliance with GDPR prior to the regulation’s effective date.
In summary, here is a list of important changes that will come into effect with the upcoming GDPR
Right to request copy of personal data
Right to be forgotten
Compliance obligations to keep detailed records on data activities
“Under the
Expanded rights for individuals, the GDPR provides expanded rights for individuals in the European Union by granting them, amongst other things, the right to be forgotten and the right to request a copy of any personal data stored in their regard.”
As Apache Kafka is one of the most prominent data streaming systems in the modern enterprise, the majority of data is continuously streaming in and out of various systems. Consider a typical Avro encoded message flowing through Kafka:
{"type": "record",
"name": "CustomerRecord",
"namespace": "com.acme.system",
"doc": "Schema for Customer Records",
"fields": [
{"name": "customerId",
"type": "long",
"doc": "The unique customerId"
}
]}
Avro schema definition allows attaching additional metadata which can be used to annotate particular fields.
By injecting "gdpr" : "customerId" to the Avro Schema, we can automate the tracking and collection of customer
data.
{"gdpr": "customerId",
"name": "customerId",
"type": "long",
"doc": "The unique customerId"
}
Now let’s review a streaming topology for a typical IoT use case.
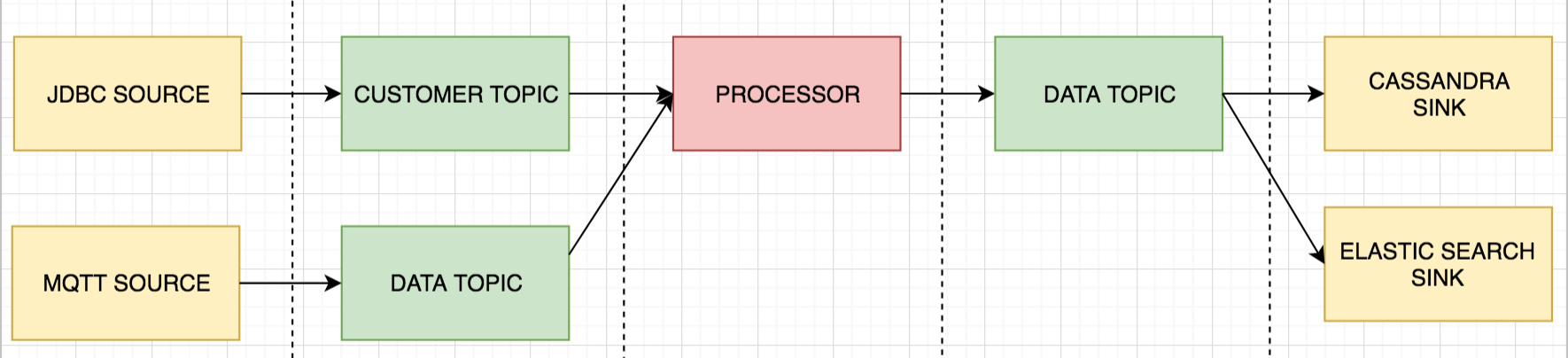
Customer data are collected via a JDBC Source and additional device events are sourced from an MQTT system. We are processing data (join, filter, aggregate) and placing them into another topic, before pushing them to down-stream data stores.
To track the data, and have “detailed records on data activities” we need to be aware of the full data lineage, even when transformations are in place:
INSERT INTO data_topic_2 SELECT customerId AS cid, ...
A Kafka SQL processor, for example can rename a field, so tracking the lineage across the topology is the mechanism
of identifying which other topics or data stores contain now customer information.
Having GDPR awareness requires as a first step, identifying all the points, where data about individuals are processed or stored. In the case of Apache Kafka, you will expect tracking i) topics, ii) connectors and iii) processors:

Topics with data about individuals

Connectors with data about individuals

Processors with GDPR data
Tracking as well as auditing all activities can allow us to respect the Compliance obligations to keep detailed records on data activities. Auditing means that we’ll have to track any processing of the data, across the entire
lifecycle and timeline of the customer’s data.
Once a request for a copy of personal data is received, based on the GDPR regulations, we will need to be in a position to retrieve all personal data for the particular individual. In the case of IoT that could include unaggregated and aggregated device data; thus becoming quite a challenge.
With a lineage aware system, that can propagate through the streaming topology the gdpr annotation, we can fully
automate the collection of personal information, both from Kafka topics, as well as target datastore systems.
Thus executing a query:

Should collect all the data related to the particular individual across all topics as well as give us a report that a particular Cassandra table and a particular Elastic Search index have the potential to contain additional information.
The right to be forgotten, becomes one of the hardest challenges because of data immutability. Apache Kafka does not
support deleting records, and although some eventual deletion is supported, it requires:
A topic to be compacted
A message with the same key and a null value to be pushed into that topic
The compaction process to eventually kick in
What we need to have (as a first step) in terms of topics, is a complete list of all the topics with data about individuals, with the associated information regarding the retention period and if the topic is compacted:

Let’s drill into the right to be forgotten with an example: A customer wishes to be entirely forgotten.
What we would expect to happen, is the customer record to be removed from the source of truth, that would be
a SQL or NoSQL database. If we are using a Kafka Connector with CDC (Change Data Capture) capabilities, the deleted
record will be picked up by the connector, and a nullable record will be pushed into the customer topic.

If the Cassandra sink or ElasticSearch sink are CDC aware, they can automatically remove the relevant records from the target systems. If the Kafka sink connector, is not CDC aware, or is writing to an immutable store (i.e. S3 or HDFS) then some additional mechanism will have to kick-in to wipe that data.
As modern data-driven businesses are running more in real-time, and Apache Kafka becoming a central component for messaging across systems, it physically becomes the point of tracking as well as enforcing the new regulations.
As Data Protection regulations evolve and fines can be up to €10 million or 2% of the company’s global annual turnover of the previous financial year, or up to €20 million or 4% of the company’s global annual turnover of the previous financial year, whichever is higher, integrating data protection ‘by design and by default’ is becoming a high priority across many enterprises that deal with EU based citizens.
This is the first of a series of articles, regarding how an organization could tackle those regulations at design time, to provide a framework to ensure that compliance is in place. If you are interested more about GDPR compliance with Apache Kafka feel free to contact us to learn more.





