MQTT. Kafka. InfluxDB. SQL. IoT Harmony.
Enhanced Data pipelines with almost no code.

Jan 29, 2018

The rapidly growing number of interconnected devices confirms the Internet of Things (IoT) is a fast maturing technology. The digital economy has its own currency and that is data. Similar to the standard currencies, data is valuable if you can use it. The IoT is a driver for being data rich. However, having the data is not quite enough; you need to be able to analyze the data and take the appropriate action.
In this entry, you will see how using Apache Kafka and Lenses can help you boost your productivity by providing you the tools to build an end-to-end data pipelines with just a few lines of SQL code.
To top that, how does it sound seeing your entire Apache Kafka-native data pipelines in one interactive graph?
I can visualize all my data pipelines over Apache Kafka in an interactive graph? Yes, by the end of this article you will see the graph in action. First Apache Kafka native data pipelines interactive graph is here.
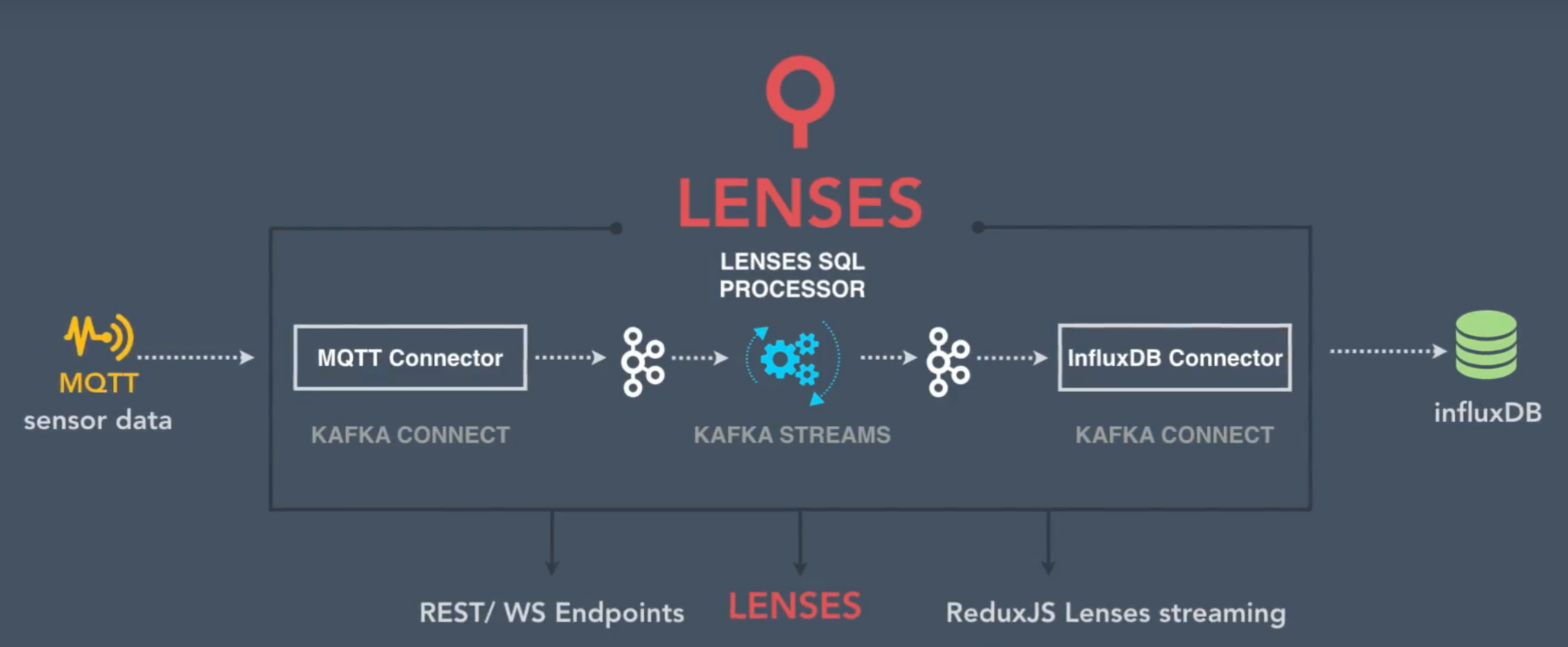
Say there is a vast network of sensors pushing various measures via the MQTT protocol to a Mosquitto cluster. Using the entire Apache Kafka ecosystem, the data is first imported into topics via Kafka Connect, then Kafka Streams comes into play to analyze the stream(-s) of data, and the results are then pushed into an instance of InfluxDB via Kafka Connect.
Let’s put together one data flow to see how quick and easy it is to build a solution for monitoring the temperature and humidity levels. Furthermore, using the redux-lenses-streaming Javascript library for bridging Kafka via SQL, you will see how you can build richer Web applications by hooking into live Kafka data.
If you prefer watching a video to reading an article, you can do so. Sit back and follow the talk
Lenses is the core component bringing everything together in a unified platform allowing you to built and monitor your data pipelines. You can get the free Developer from https://lenses.io/start.
“Lenses is a data streaming platform built on top of Apache Kafka, allowing you to stream, analyze and react to your data faster. You can boost your business by delivering faster, better and easier without having to be a Kafka-savvy person.”
Leveraging the platform’s Kafka Connect management capabilities, Kafka connectors and its powerful 3-tier SQL engine for Apache Kafka, you can build a streaming ETL in minutes.
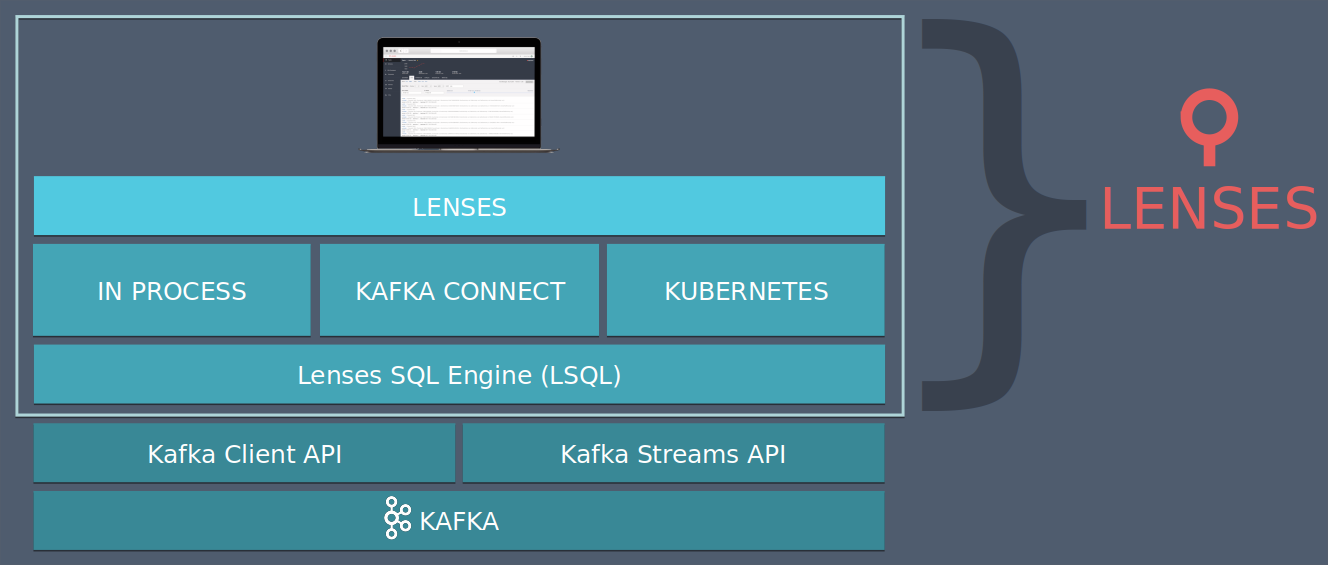
Lenses SQL(or LSQL) is a powerful SQL engine for Apache Kafka covering both batch and streaming capabilities. What that means is simple: you can write Kafka Streams applications with Lenses SQL or you can browse Kafka topics data at ease.
At a very high level, here’s the rundown of the major components that fall under the Lenses SQL engine umbrella:
“Lenses SQL has made writing Kafka Streams applications or browsing Kafka topics a lot easier.”
Before going any further, make sure you have your Lenses instance ready. You can follow this link to get your developer edition in case you don’t have it already. Please note you need Docker available on your machine. When you register for the free Developer Edition, you get an email from us with the details of how to run it. The command is similar to this:
For our data pipeline, we need to use the latest MQTT source connector which handles JSON payloads as well as setting the Kafka message key to the value of our sensor id, for example. The current MQTT source deployed with the free edition contains an older version of the connector which doesn’t allow setting the Kafka message key. The next release will have this covered and the steps below can be skipped. Meanwhile, to get the latest code please follow these simple steps:
Download the MQTT connector jar from our Stream Reactor github page.
Store the jar to a known location (we are going to use it when we start Lenses) for example ~/work/mqtt-connector/
You need to start the Docker image with the distributed MQTT connector disabled and using the latest jar. Here is the command to do so:
You might have noticed the two extra parameters added to the command received in the email:
-e DISABLE=mqtt \ Disables the already packaged MQTT connector.
-v ~/work/mqtt-connector:/connectors/mqtt-connector \ mounts your local folder and makes the latest code available to the Docker instance.
Run the command.
The Docker image delivers the Kafka environment required for local development: 1 Kafka Broker, 1 Kafka Connect Worker, 1 Zookeeper Node, Schema Registry, and of course the Lenses.
You don’t have to install or configure anything else to start coding against Apache Kafka.
It takes around 45 seconds or so for the environment to be available.
Make sure you do allocate at least 4GB of RAM for your Docker process. Open your favorite browser and navigate to http://localhost:3030 to access the Web user interface.
The first requirement for our data pipeline is having sensors data. To mimic a real cluster of sensors sending data over MQTT, a data generator application is provided. To avoid setting up the MQTT Mosquitto cluster, the application embeds a lightweight MQTT compliant broker by leveraging the Moquette library.
Below you can find the shape of data a sensor sends over. By the way, the programming language used for the generator code is Kotlin.
The code is quite easy to follow even if you haven’t used Kotlin before. First, the MQTT broker is started on the given port. For simplicity it allows anonymous connections:
Then, in a while loop, the code generates and sends data as if there were 4 IoT sensors. For the purpose of this demo, we keep the sensors number small since it will make it easier to follow the data.
You can find the code on GitHub. To save you the time for building it, the application artifact is provided here. Once you have extracted the archive to your machine, navigate to the folder and run the following command:
./bin/mqtt-sensor-data 1883 /sensor_data
There are two parameters provided. The former is the port number to bind the MQTT broker to, and the latter is the topic name to send the data to. Running the application should result in a similar content printed on your console:
There is data to work with now.
Apache Kafka comes with the Connect framework which allows moving data in and out of Kafka reliably and at scale. We will use our MQTT source connector to ingest the sensor data into Kafka. You can find more about the connector by reading the documentation here.
The connector subscribes to the MQTT topic and writes the data it receives to a Kafka topic.
Its behavior is driven by an intuitive SQL-like configuration we call KCQL (Kafka Connect Query Language).
It is part of Lenses SQL engine and provides functionality targeting Kafka Connect.
This greatly reduces the complexity of managing the configuration, while, at the same time, it allows to quickly understand
the work the connector is doing.
Let’s create the MQTT source connector instance and see the data flowing through to the target Kafka topic. Make sure are logged-in into the Lenses Web UI, and navigate to the Connectors page (you will find the link on the left-hand side menu). Once loaded the page looks like this:

To add a new connector, click on the +New Connector button (at the top right of the page).
From the new screen presented to you do select the MQTT entry from the Sources list.
Once that is done, you will be taken to a different page prompting you to provide the connector configuration.
Take the settings below and paste them into the configuration editor and then click the Create Connector button.
Before continuing let’s pause a moment to understand what the configuration is describing.
connect.mqtt.hosts=tcp://127.0.0.1:1883 configuration entry specifies the MQTT connection detail.
If you have used a different port to start the data generator than 1883, the above configuration needs to be updated.
The KCQL syntax (see below) instructs the connector to read from the MQTT topic /sensor_data and push the entire payload to the Kafka topic
sensor_data.
The resulting Kafka message will have its key part set to the incoming payload field id- the sensor unique identifier.
Translating the MQTT message to a Kafka message is handled by the JsonSimpleConverter class.
It takes the JSON MQTT payload and translates it to a Connect Struct which is handed over to the Connect framework to push to Kafka.
We are ready now to create the connector. Click on the Create connector button and wait for the Connect framework to do its work and spin the MQTT source task.
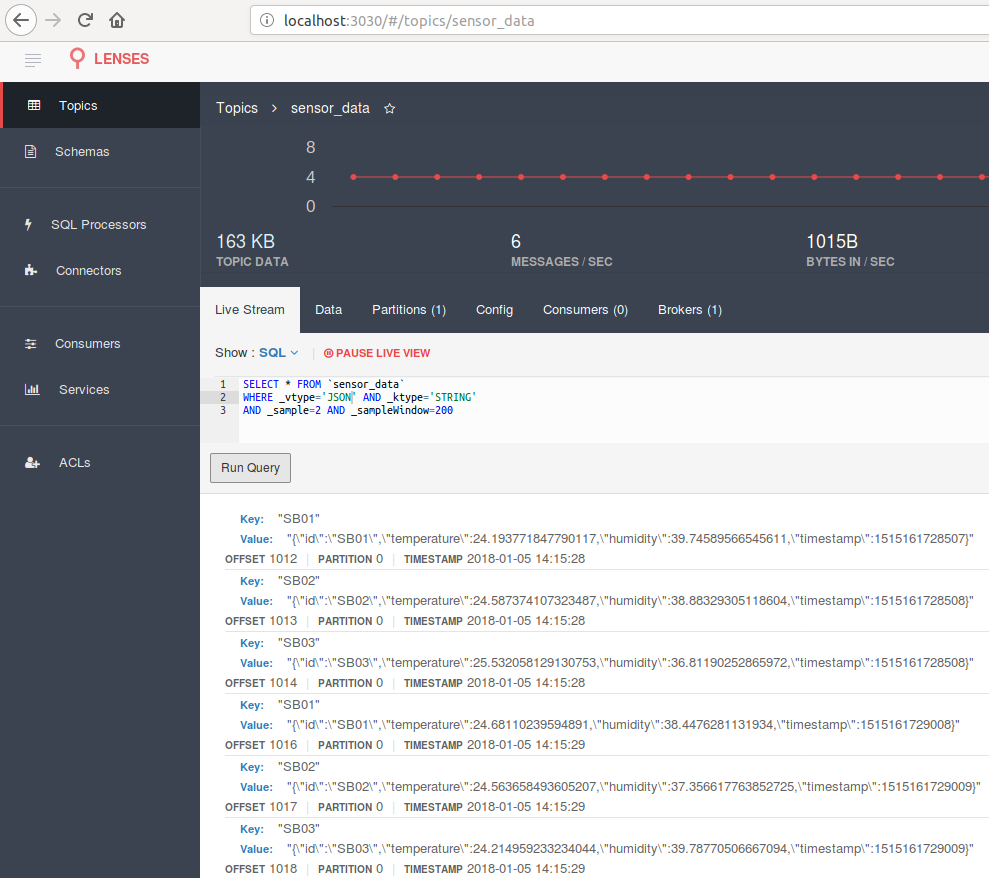
Once is running (should take a few seconds for the task to be allocated — we use only 1 in this case), you can navigate to
http://localhost:3030/#/topics/sensor_data to see the data as it arrives in Kafka.
The data pipeline is quickly taking shape. Next, we want to analyze the data an calculate the average temperature and humidity values while retaining the min/max over a given time window.
To analyze the data stream, we need a Kafka Streams application. Using Lenses SQL, we can quickly define and run such an application in minutes. Apart from allowing SQL to describe your application, the Lenses platform also takes care of running and scaling the resulting Kafka Streams applications.
For the Developer Edition, the KStream app runs in the same process as the platform main process. The Enterprise version offers two additional modes for execution and scaling: Connect and Kubernetes. You can watch how the
looks and get started with the documentation.“Running, monitoring and scaling the Kafka Streams apps defined via Lenses SQL is provided out of the box.”
To create the application processing the data stream, navigate to the Processors page.
SQL processor is the platform terminology to describe a Kafka Stream applications written with Lenses SQL. Press the New Processor
button to create a the application.
Grab the code below and paste it in the editor while naming the processor as IoT:
“You don’t have to be an Apache Kafka expert or a JVM developer to write a stream processing application.”
Let’s go over the code. The SQL-like syntax will end up being translated to a Kafka Streams application which calculates the average, min and max values for temperature and humidity. The calculations are done over a time window of 2 seconds. This means every 2 seconds there will be a result for each sensor who sent data.
Before the INSERT statement there are three SET ones:
autocreate=true; instructs the SQL engine to create the target topic if it does not already exist *
auto.offset.reset= `latest`; means the application will process the data from latest messages onward. *
commit.interval.ms =3000; sets the frequency with which to save the tasks position (offsets in the source topics)
You might ask yourself: Why two SELECT statements? The simple answer is: calculating average. We are working on supporting for an avg function. Once that will be available, the above code will be even easier to write. The first SELECT statement builds a KStream instance which calculates:
the total number of messages received over the 2s interval
the sum of all the values for humidity and temperature
the min/max values for humidity and temperature
for each sensor (see the key being referenced in GROUP BY …, _key) it receives data for.
Utilising the data generated by this first statement, the second SELECT statement can calculate the average temperature/humidity by computing temperatureTotal/total as avgTemperature.
By clicking now on the Create Processor button you should end up with with the web page looking similar to this:
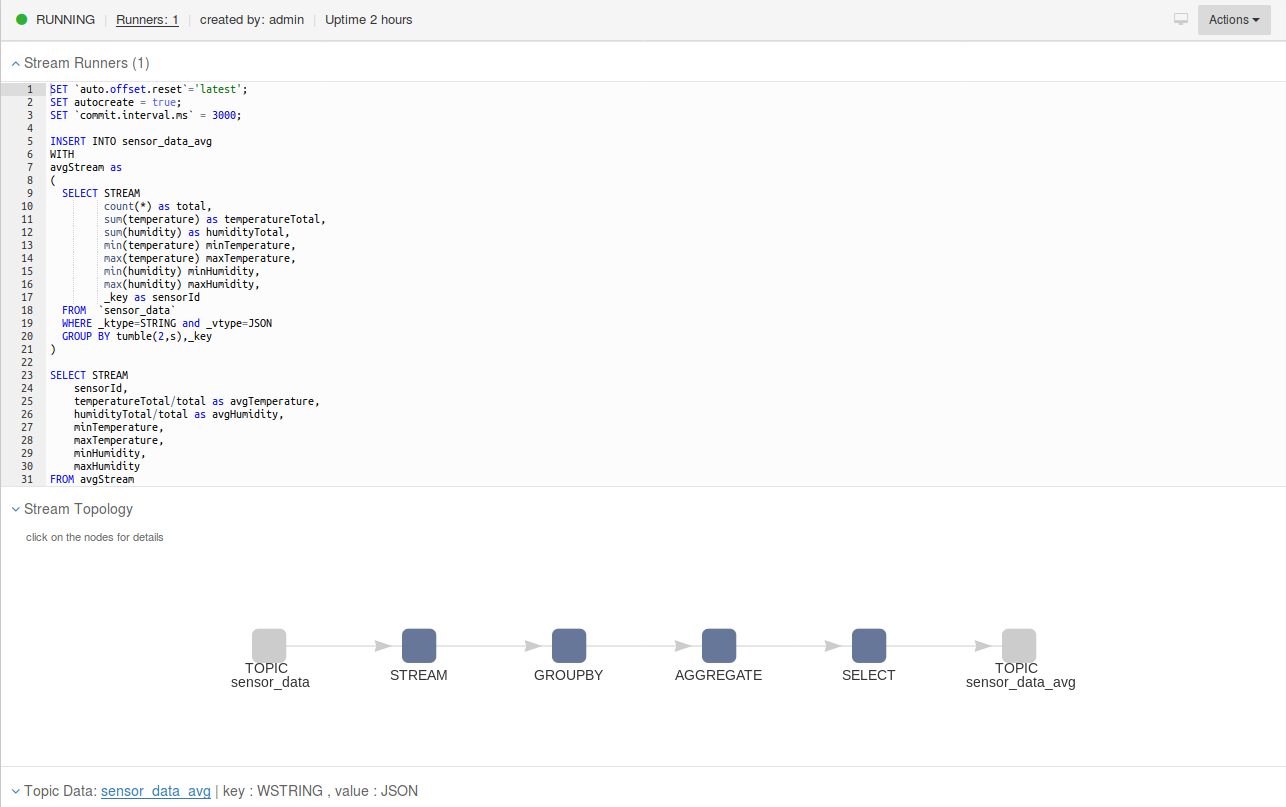
The stream topology graph is provided for each SQL processor.
Now the processor is up and running, you should see data already pushed to the target topic. The UI will display the data arriving in the target topic in real time. Furthermore a user can interact with each node in the graph.
Simple, quick and easy.
To complete the data pipeline, a Kafka Connect InfluxDB sink will persist the stream analysis results.
InfluxDB is an open source time series database able to handle high write and query loads. Written in Go, it can handle large amounts of data such as application metrics, IoT sensor data, and real-time analytics. At Lenses.io we provide the most advanced Kafka Connect Sink for it. You can find more about the sink capabilities in the documentation.
Before setting the sink, you need to have an instance of InfluxDB running. The best and fastest way to do so is to use the existing Docker image for it. Run this command to provision your instance:
Once the Docker image is running you need to create the database to insert the data into.
Run the following command to create a database named IoT:
To provision the sink, you need to navigate to the UI Connectors page as you did for the source.
This time, when adding a new connector, select InfluxDB from the Sinks list.
When the UI prompts for the connectors configuration, paste the information below:
Using the configuration above, the sink knows to connect to the local InfluxDB instance and insert the data into the iot database.
The connect.influx.kcql configuration entry specifies, via a simple INSERT statement, the target InfluxDB measurement and
the source Kafka topic to read the data from. WITHTAG keyword will trigger the sink to provide two labels for each inserted data point.
The first one, id, contains the sensor unique identifier; the second one poweredBy is a constant.
Since KCQL hasn’t specified the timestamp field (InfluxDB requires a timestamp set for each data point) the point will get the time at insertion expressed in nanoseconds.
Click the Create Connector button to see the connector instance provisioned and the computed averages written to InfluxDB.
Kafka Connect will allocate the task and the connector will start pushing data to the time-series store.
To query the data from InfluxDB run the following command:
and you should see content similar to the one below being printed on your console:
Voila! Our data pipeline is now running. You had the patience and curiosity to get this far, but there are two more points to touch upon, and they are quite important.
Having data flowing through the database is great, but what if you want to tap into the data as it is computed and present it in your Web application? That could lead to richer user experience, and your users will greatly appreciate live time dashboards/charts.
The platform comes with the Javascript library to do just that. Soon to be open sourced, it allows you to connect to Kafka and get live data into your browser leveraging Redux and Lenses SQL.
A sample application is provided to showcase the things you can achieve. You can find the code on GitHub. Once you have downloaded it locally, run:
and then navigate to http://localhost:8000/lenses/.
Use this connection string: wss://localhost:3030/api/kafka/ws and the admin/admin credentials to open a connection.
Authentication is required by default when accessing the REST API the platform exposes.
You can find more about the library and the exposed endpoints in the documentation.
Type the following Lenses SQL statement in the query editor:
SELECT * FROM sensor_data_avg WHERE _ktype=STRING and _vtype=JSON
Shortly after you should see live aggregated data being rendered on the chart:
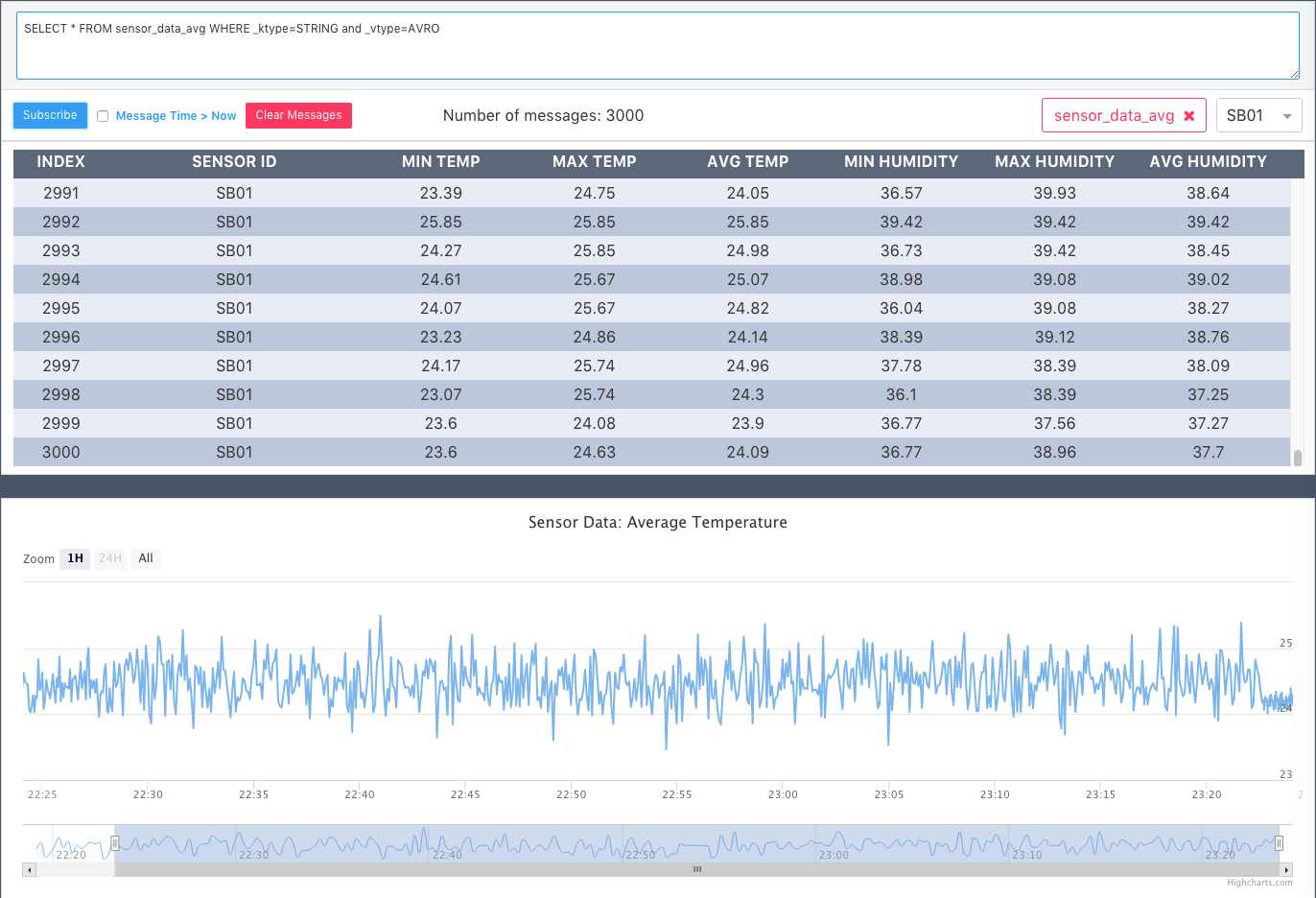
Pretty cool if you ask me!
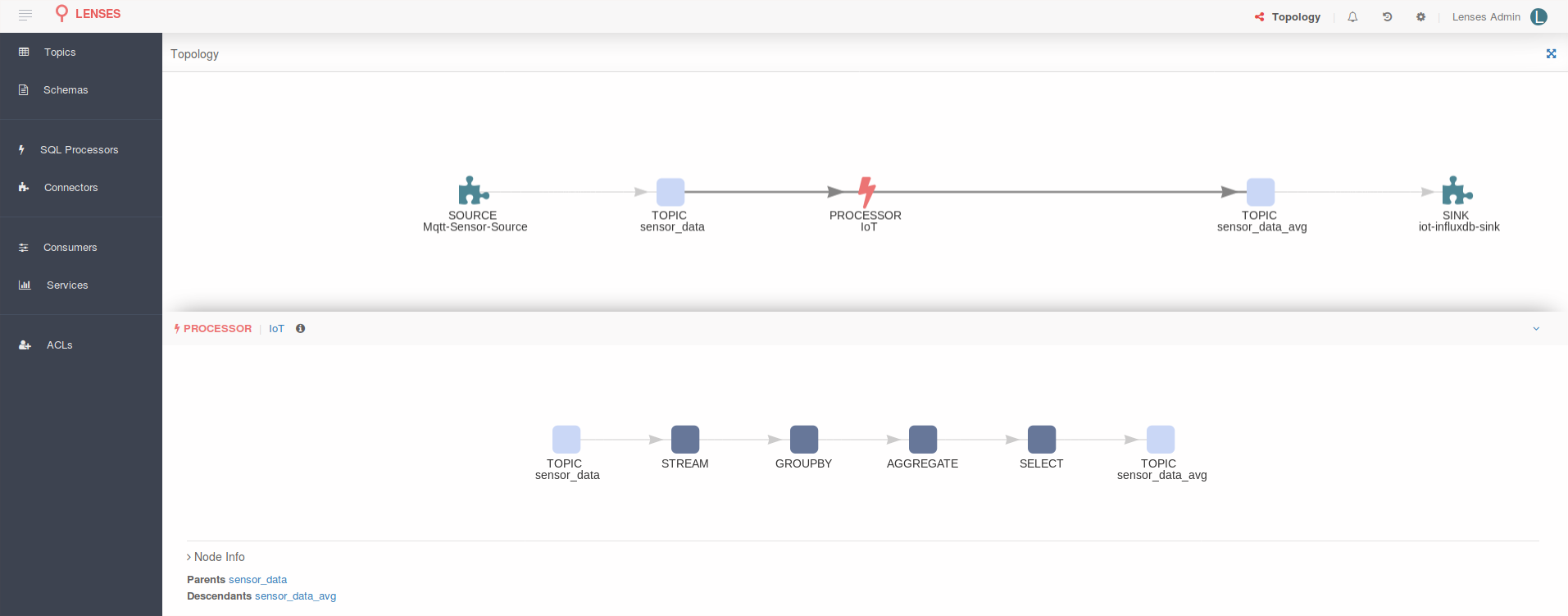
There is something left for the end of this entry. And is something we are very happy to have achieved. What if you were told you can see the entire topology in a nice graph: the Connect source pushing data into a Kafka topic, a SQL processor (Kafka Streams App) doing the analysis and storing the data back to another topic from which a Connect sink sends it to InfluxDB? Navigate to http://localhost:3030/#topology and be amazed:
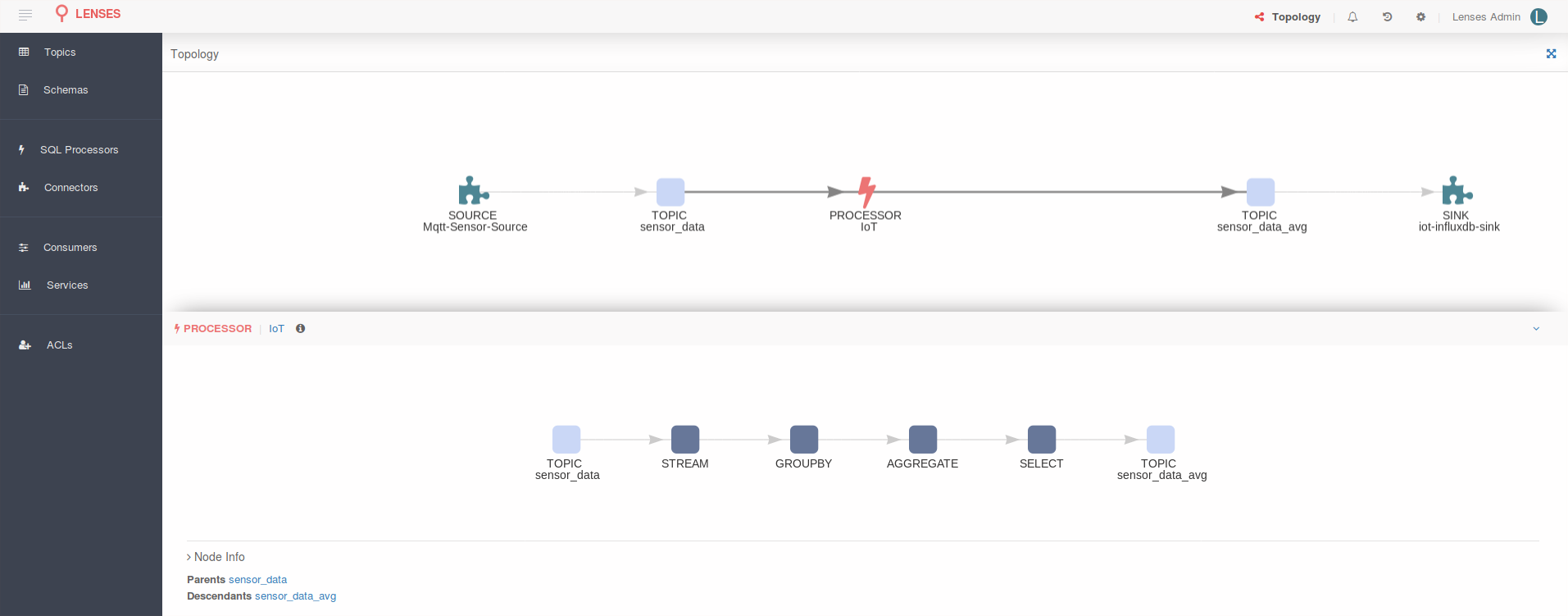
Pretty cool, if you ask me. The more connectors or SQL processors you add the more complex the graph will become. You can visualize your entire data flow in one interactive graph!
Lenses is the first product to offer native Apache Kafka data pipelines interactive graph! Yet another first for Apache Kafka delivered by Lenses.io.
Selecting a node in the graph would provide the specific details of that data processing step:
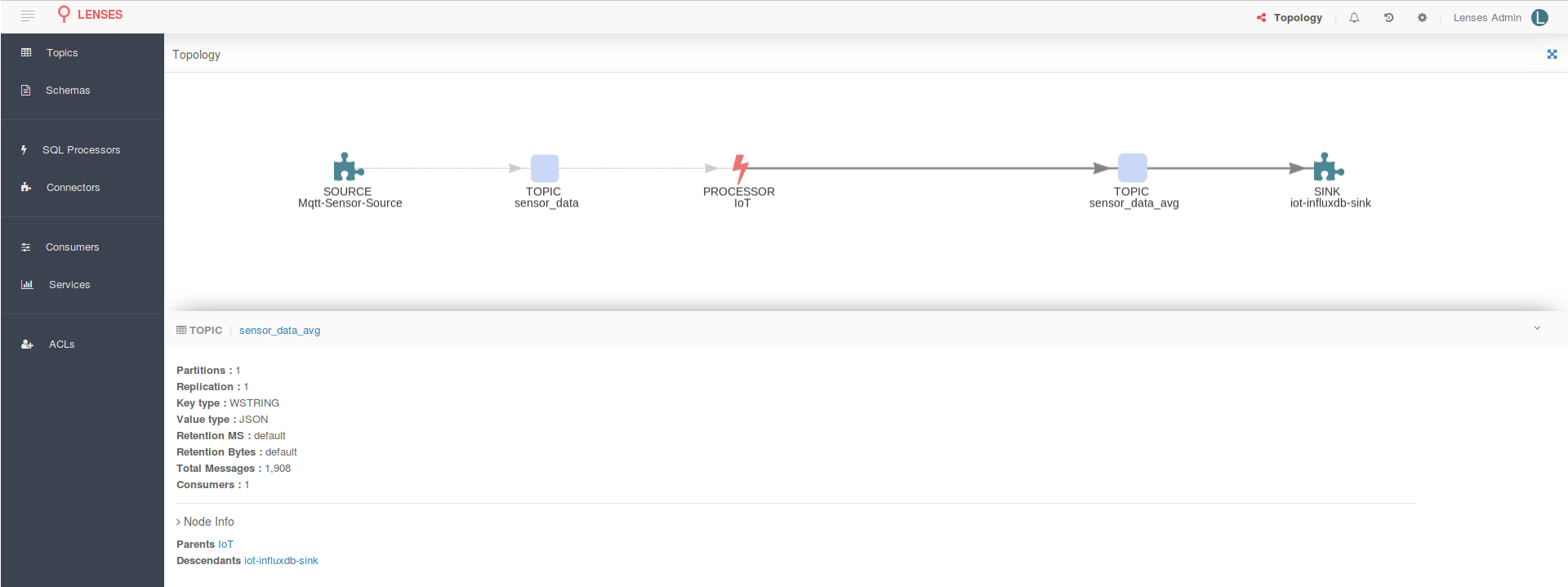
Data pipeline graph - Kafka Connect connector
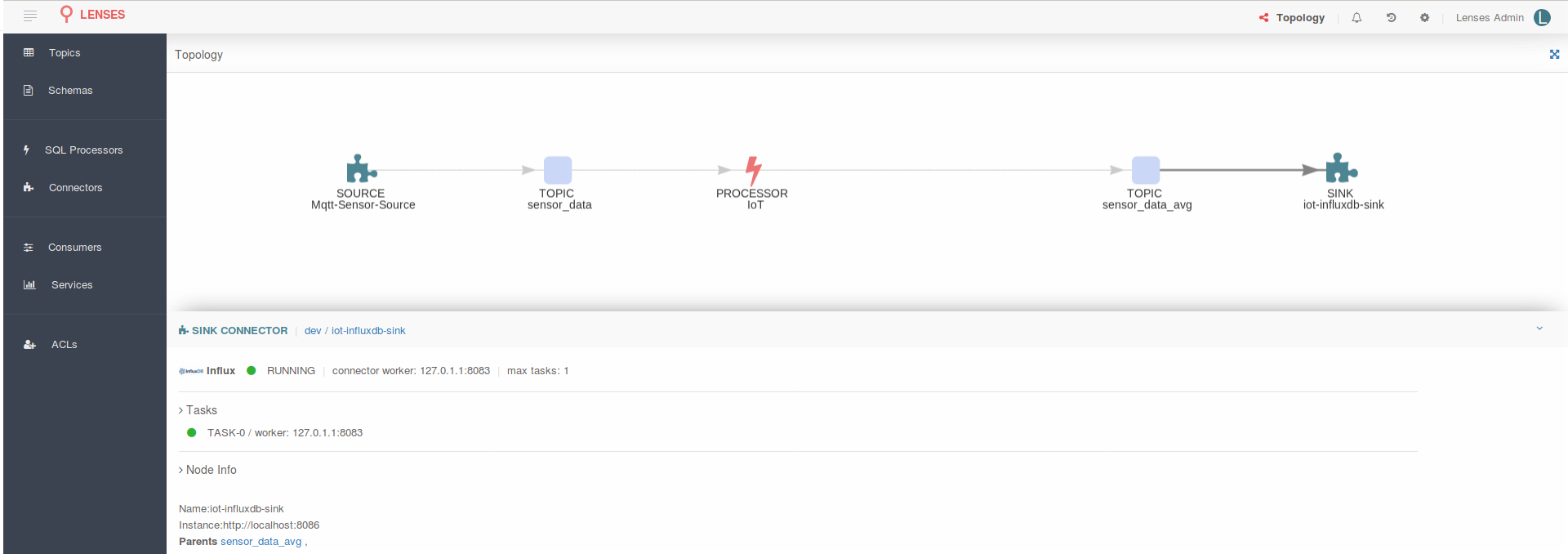
Data pipeline graph - Topic selection
We have seen how the Lenses platform enriches the Apache Kafka ecosystem by providing the tools to easily and quickly set up a data pipeline. There if more to it than just that. You can find more on the website. The topology view gives you the entire picture of your data flows. We can’t probably stress enough the benefits of seeing your data pipelines in one place. Using the platform you can deliver your streaming solutions, in this scenario for IoT, a lot faster and a lot easier.
Focus on your business requirements, we provide the tools.
Stream. Analyze. React. Lenses!
If you want to learn more about Lenses, just contact us @lensesio or via email info@lenses.io, or simply chat live on https://lenses.io




