Data Governance and GDPR
Data Governance conformance with Data in Motion

May 04, 2018

Last December we announced our commitment to provide the necessary capabilities for data streaming systems, that will enable data-driven businesses to achieve compliance with GDPR prior to the regulation’s effective date (May 25, 2018), and this post explains how Lenses provides Data Governance capabilities and GDPR compliance by design.
The immutable nature of modern high-performance distributed systems, provides a lot of competitive advantages to various industries that are interested in fast loading streams of events and apply low latency queries and scalable processing for data in motion. Regulations such as the GDPR and Data Governance challenges, are making it non trivial to build compliant applications on such systems, as these become critical paths of the architecture.
Many companies are looking to make GDPR compliance easier and faster for their streaming data architectures. Our team brought all the experience from the financial industry and top tier investment banking (where regulations are treated as a first class citizens) in Lenses to provide everyone Data Governance by design.
Lenses is a data operation platform that enables data literacy, discovery, management and movement of data across systems and processes. As an overlay technology, it offers amazing visibility and control over all streaming data and technologies. It provides the necessary abstractions and best practices and at the correct layer and thus future proofs your data system. At the same time provides a default and secure gateway to safely share data in motion among users or applications. Lenses embraces Apache Kafka and Kubernetes, and provides a number of open source components to achieve so.
Lenses with its industry-leading SQL engine, is well placed to support data protection compliance and help companies meet evolving data governance demands with streaming data.
If we take a step back from GDPR, modern data operations that include streaming components like Kafka should ensure data availability, integrity and security and at the same time protect and govern the usage of Personal Identifiable Information (PII). What customer information do I have? How we receive this data? Who has access or looked to the data? How to report this information? And the list goes on!
By treating security as a first class citizen for all User Access Rights & processes, Lenses ensures exactly who should be allowed to use the data and enforces the access rights
across all data in motion. Authentication and Authorization are supported by either basic Role Based Access or LDAP and Active Directory (or Kerberos / TLS certificates).
Effective access control is enhanced via black list and/or white list permissions assigned to User Groups or individual users, for particular data sets.
In addition to that Access Control Lists and Quotas make large multi-tenant environments safe and secure. Using Lenses you can now govern
your data-in motion, while controlling finely who has access (read or write level) and how data is used.
Lenses continuously monitors every aspect of the system and user activity, and captures detailed records of every action or data-access pattern, in an immutable audit log. Every action like creating, amending or deleting a topic, processor, connector or admin changes like ACLs or Quotas or changing a configuration is tracked. Lenses also monitors the data access activity, whether this originated from the Lenses web interface, a REST / WS call, CLI, BI tool. The audit log protected with an ACL (Access Control List) rule, means that only the authorized users may access it, but is also queryable so that we can easily answer the WHO did WHAT and WHEN.

With Lenses role based access, security checks and auditing is enforced and other services can be protected at a network level. Lenses periodically watches all resources and identifies such actions and its timestamp, to make sure we capture operations occurring directly to the systems.
In addition to monitoring you data in motion, Lenses can be used to trigger relevant Alerts in order to notify you, about particular activities, such as deleting or adding a new dataset, or removing existing records. Alerts on specific user and system activity can further ensure data availability and integrity.
Now let’s focus on the 3 main principles GDPR: i- Right to retrieve data ii- Record data activities iii- Right to forget
One of the fundamental requirements of GDPR is the Right to Retrieve Personal Data. Lenses Data Policies provide an amazing experience for tracking your PII data, identify which topics contain PII data, and also track who and what process is using PII data.
Lenses SQL then allows you to easily “Retrieve Data” from these topics:
SELECT * from topicA WHERE customer.id = “XXX”
Lenses retrieves and deserializes the data to a human-readable format. You can use the User Interface or use the APIs or the Command Line Interface, or one of our libraries (JDBC, Python, Go). Get up to speed with tuning streaming queries here.
Data access, is protected by global data policies. Any protection levels applied by the Data Officer, will ensure that all sensitive data can be accessed and shared securely and safely via the presentation layer.
GDPR introduces an interesting challenge here. The need to preserve detailed records on data activities. Lenses has an amazing topology view that addresses exactly this challenge. Most data projects contain multiple systems, data technologies, microservices or AI modules. Hook any technology and component into your topology view:
1 - How data flows through your data pipelines
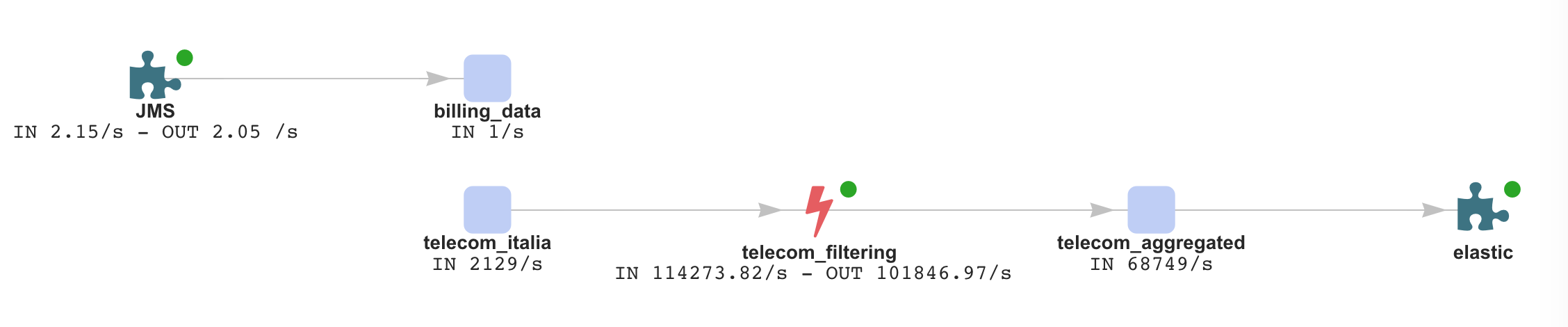
2 - The internal representation of streaming processing / Lenses SQL

The above two views, contain important information such as the topology view with status, metrics and SLA on all data pipelines, and also the internal topology, that provides details related with data processing activity.
The combination of the above are the Records of data activities as per the GDPR specifications. All Connectors for Kafka and Lenses SQL / KStream applications are continuously monitored and the topologies are fully interactive so you can inspect every level of your data systems.

Anonymizing data is a very simple operation with streaming SQL:
And you can delete all the records on a topic/partition to a specific offset if using Kafka 1.0 or later, both via a user experience interface or from the Delete API. You can also DELETE data from compacted topics using the DELETE syntax:
DELETE FROM topicA WHERE _key.deviceId = ‘123’
For compacted topics, you need to be aware that Apache Kafka will eventually remove those records. For records to be evicted we need a newer record with the same Key as the record to delete and with null as its value. Periodically and in accordance to configuration the brokers will roll the segments, thus deleting old records.
Apart from the above, physically deleting data from an overall immutable system like Apache Kafka is limited. What you can do using Lenses SQL Processors, is create a new topic with a copy of the data of the source topic, while excluding particular records:
And then delete the old topic and start using the clean one. It is a short-cut, and requires some practice in order to be in a position to tackle this currently. Hopefully the capability to really delete records from a Kafka topic will be introduced in a future release, thus enabling fully the seamless deletion of data from topics.
The challenge of GDPR was managed systematically and at design time. By installing and enabling Lenses on a Kafka cluster, you get automatically data governance capabilities, as well as a number of other industrial level tooling to manage and operate your data in-motion. This means, streaming real-time data while ensuring Enterprise Governance and Data Compliance. It also means that individuals can easily find the necessary data and integrate their application.
Our collective journey through GDPR is far from over; we will continue to innovate, talk to, and —most importantly— hear from the community and every future release is going to provide additional capabilities for Data Governance.
You can try out Lenses by contacting us and we will shortly send you the download link, or request a demo for your team.





