Schema Registry UI for Kafka
Schema-registry-ui is a fully-featured tool for your underlying schema registry that allows visualization and exploration of registered schemas. Find it on Gihub

Aug 05, 2016

Hey,
If you are looking for an all in one UI for Kafka check out Lenses for topic data, schemas, connectors, processors, consumers UIs and Lenses SQL engine support!
If you are looking for a safe way to interchange messages while using a fast streaming architecture such as Kafka, you need to look no further than Confluent’s schema-registry. This simple and state-less micro-service, uses the _schemas topic to hold schema versions, can run as a single-master multiple-slave architecture and supports multi data-center deployments.
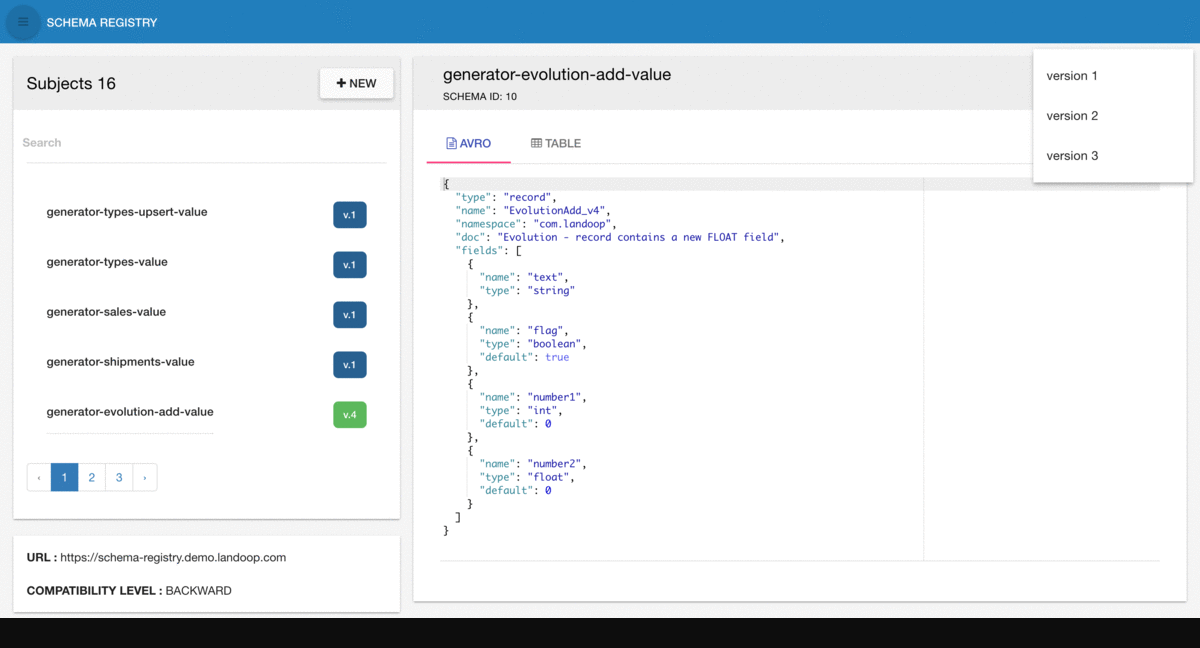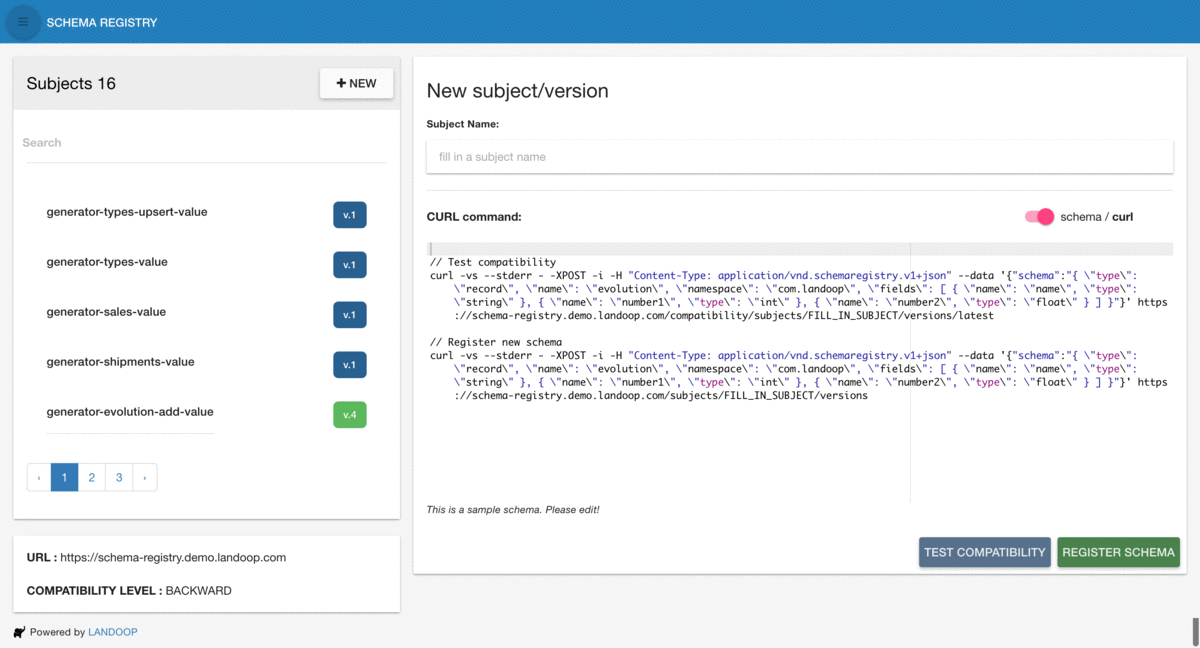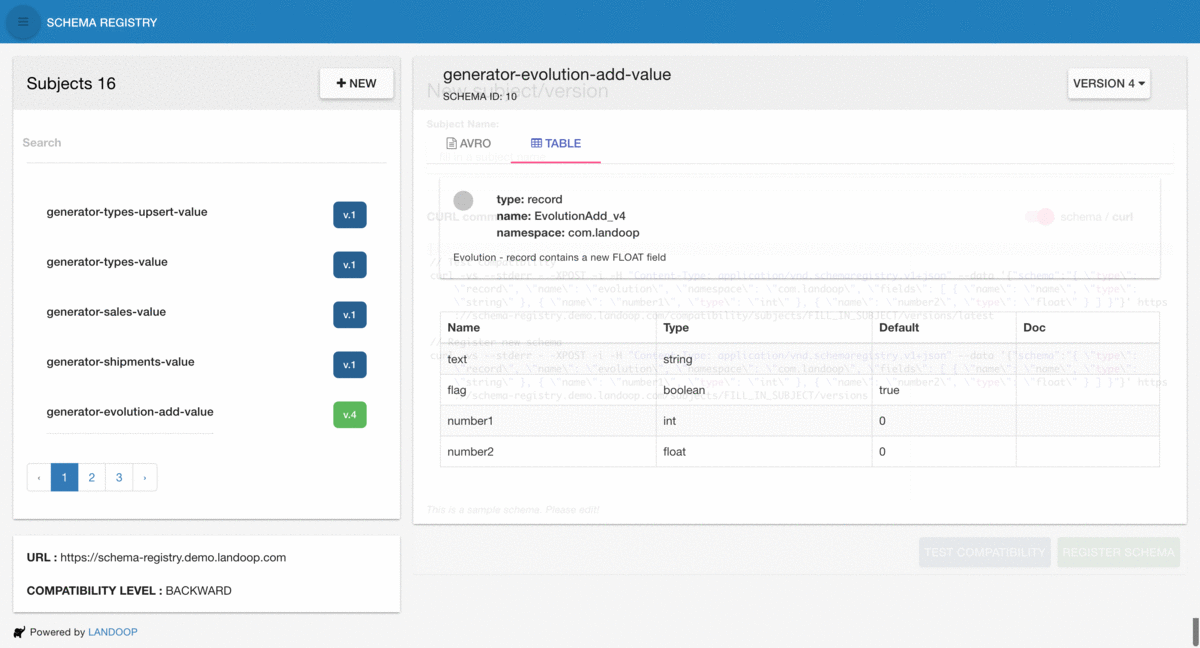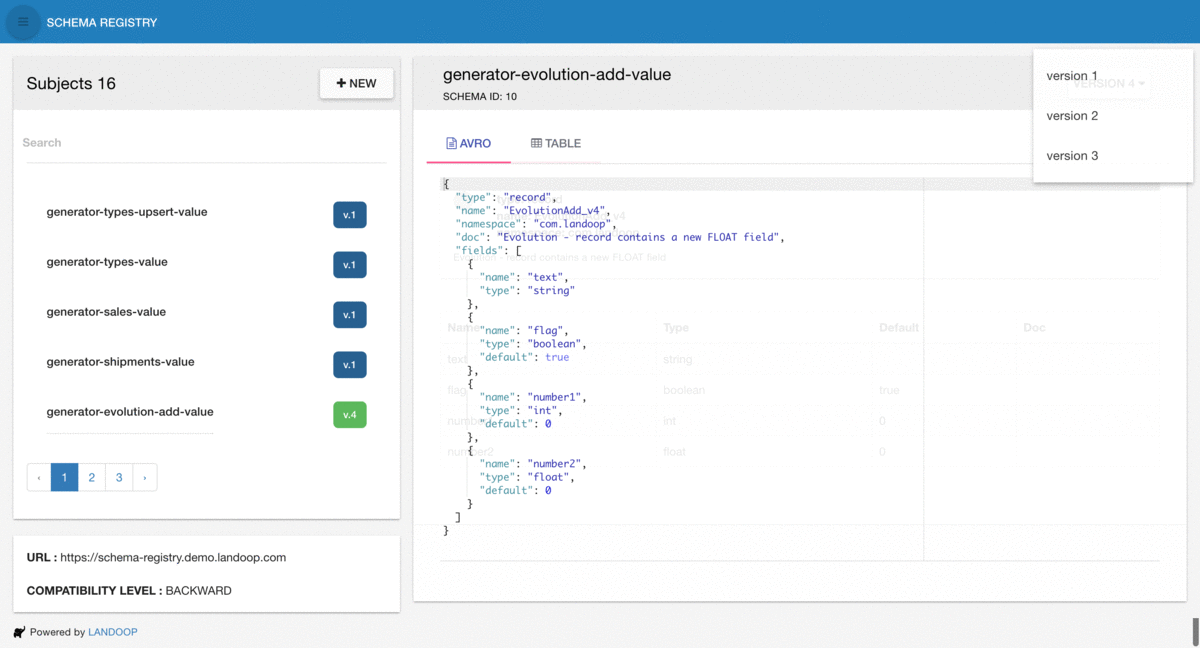
We are happy to announce a UI, the schema-registry-ui a fully-featured tool for your underlying schema registry that allows visualization and exploration of registered schemas and a lot more…
In a nut-shell the schema-registry-ui provides
Exploring and searching schemas
Avro evolution compatibility checks
New schema registration
Avro + Table schema views
Displaying CURL commands
A 15MByte Docker image
You can just grab a release of the latest code from https://github.com/landoop/schema-registry-ui and follow
instructions on how to serve it over an HTTP server (Tip: Remember to enable CORS). The easiest way to get it running is using docker:
And run it, by specifying where the url of the schema-registry service:
A few words about Kafka and the schema-registry and the value it adds to your streaming platform.
Overall Kafka is not picky about what data you post to a particular topic. In that sense you can send into the same topic both JSON and XML and BINARY data, and usually people just send a byte[] array created by the default serializer.
However multiple down-stream applications are consuming data off Kafka topics, and thus if by mistake (and that can happen quite easily even on a production Kafka cluster), some un-expected data are sent into a Kafka topic - you can expect all multiple down-stream applications to start failing, as they won’t be able to process the particular message. Given that Kafka does not allow deleting messages, this could result into serious pain.
Hopefully, some engineering that enforces best practices, such as sending Avro messages while allowing schema’s to be evolved can resolve all those issues, and at the same time provide a central point for your organization to explore and manage data:
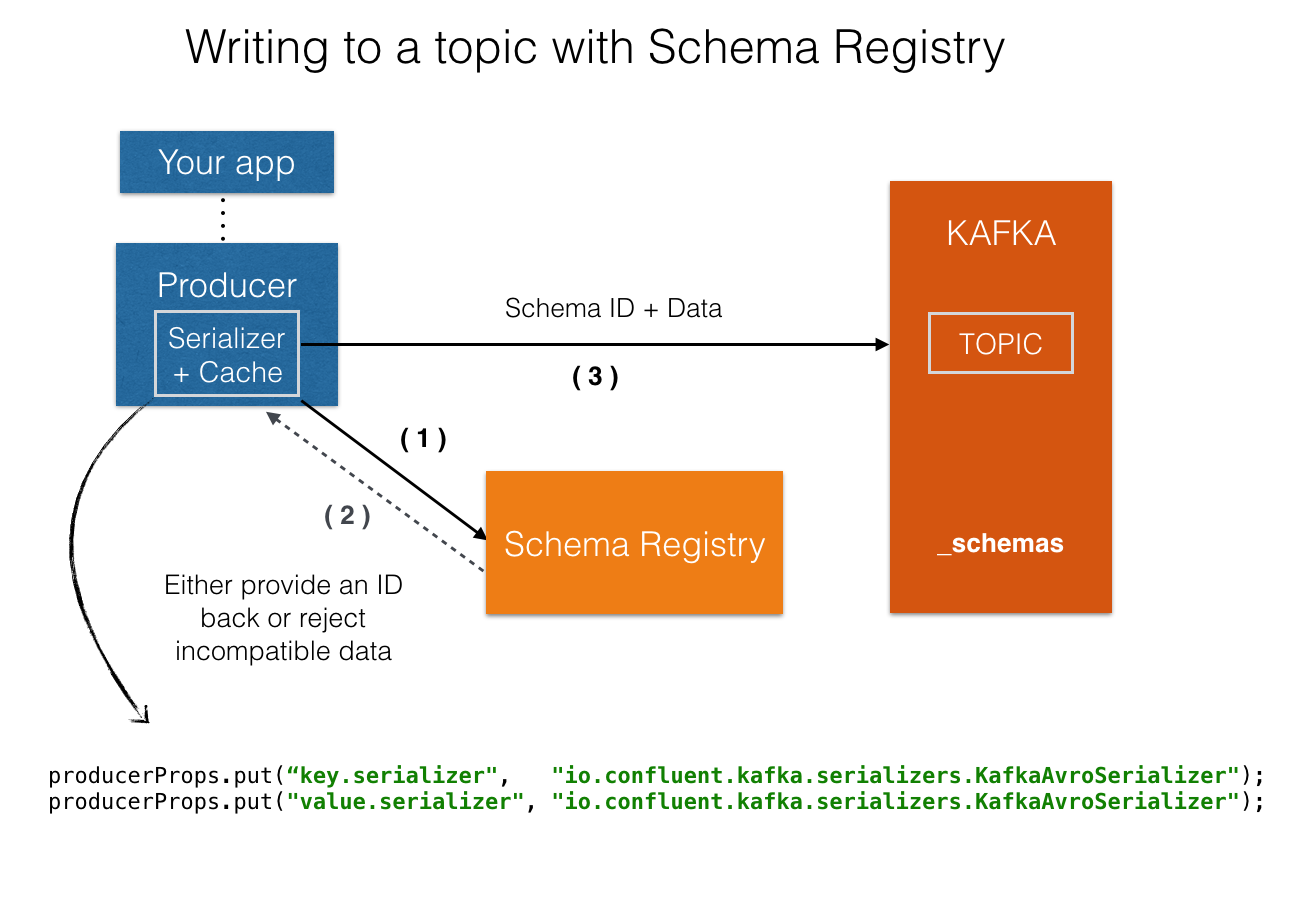
The idea is that by using i) Avro message, ii) the Kafka Avro serializer and iii) the schema registry, you can
introduce a gate keeper that not only registers all data structures flowing through your streaming platform
but at the same time, rejects any malformed data, while providing storage and computational efficiencies!
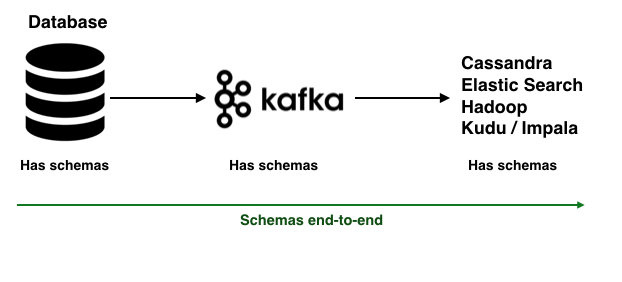
And effective run an infrastructure with schemas end-to-end :)
The schema-registry is gaining momentum and some interesting reads to get you further are Yes Virginia! Kafka stream processing really needs a schema registry and A Dog ate my schema
Hey, If you are looking for an all in one UI for Kafka check out Lenses for topic data, schemas, connectors, processors, consumers UIs and Lenses SQL engine support!
Landoop - similarly to you continuously brings to light best practices while thriving for operational excellence and the schema-registry-ui can assist you in:
Tackling your enterprise data management challenges
Maintaining resilient streaming pipelines
Allowing safe schema evolution
Proving easy data discovery
for Apache Kafka® FREE for Developers!! Download Now
Kafka topics ui for rest proxy v2
fast-data-dev, Kafka development environment





