Lenses 2.1 Release
Lenses 2.1 Release focuses on fortifying our SQL engine’s capabilities, the all-new global streaming topology graph and an improved user experience

Aug 09, 2018

August just became more hot; with great pleasure we —team Lenses— announce the immediate release of Lenses 2.1. Following an ambitious road-map, this version focuses on fortifying our SQL engine’s capabilities, the all-new global streaming topology graph and an improved user experience.
The Lenses SQL streaming engine for Apache Kafka can now handle any type of serialization format, including the much requested Google’s Protobuf.
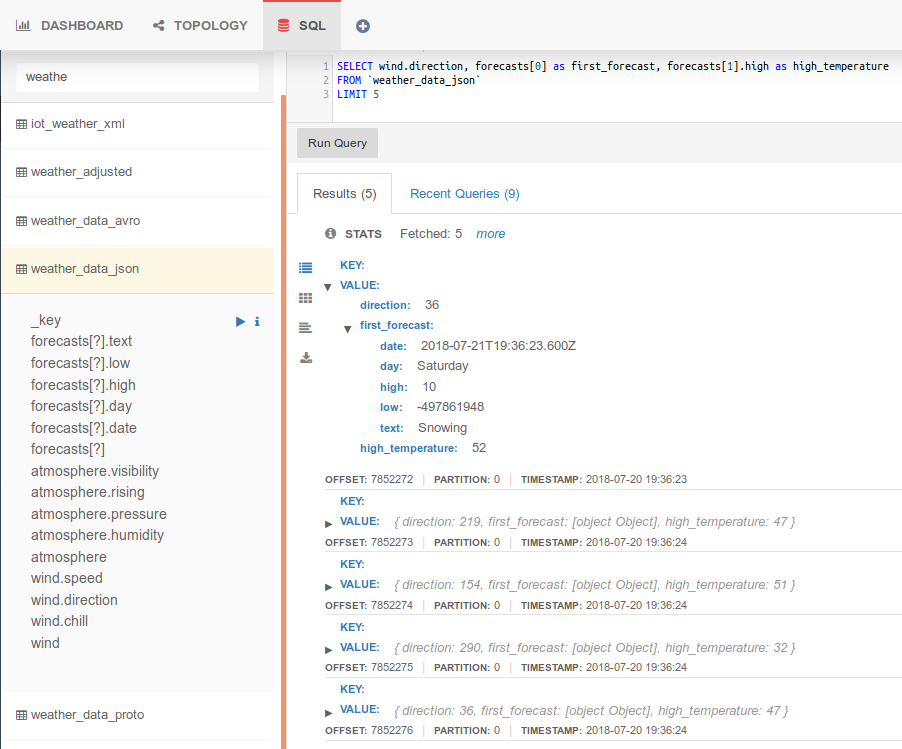
Native support for streaming XML payloads. While assisting a financial institution to manage and process millions of continuously streaming XML messages, we introduced XML support to Lenses SQL queries. Lenses 2.1 brings this capability publicly available. Click here for an example on how you can now leverage streaming SQL on Kafka XML data.
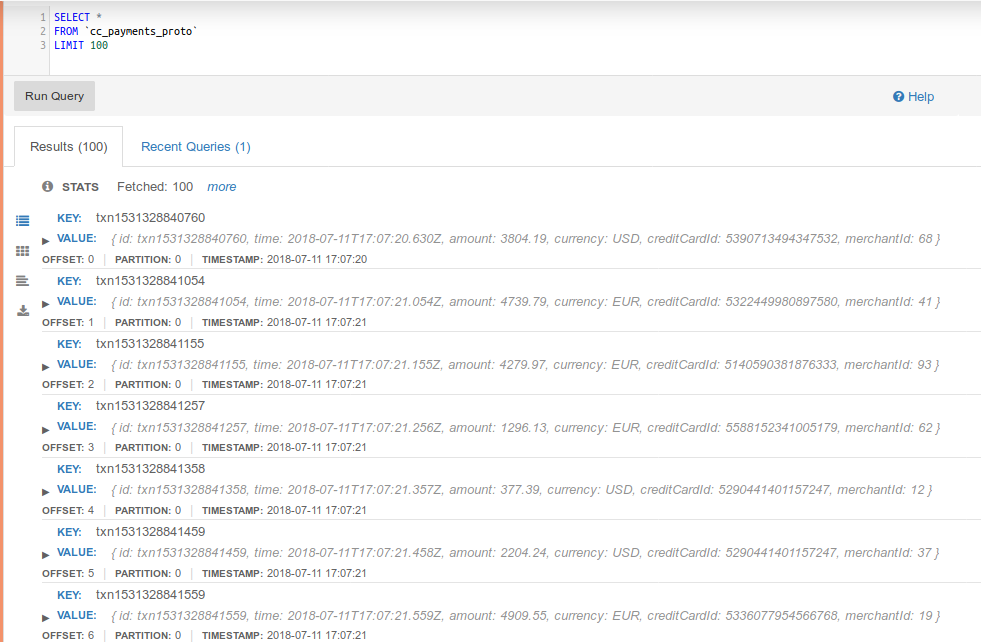
Avro and JSON payload types may be the most advertised options when it comes to serializing Kafka records. However, many companies rely on Google’s Protobuf or their own serializers. Here’s an example of running a bounded query for a topic containing records stored with Google’s Protobuf:
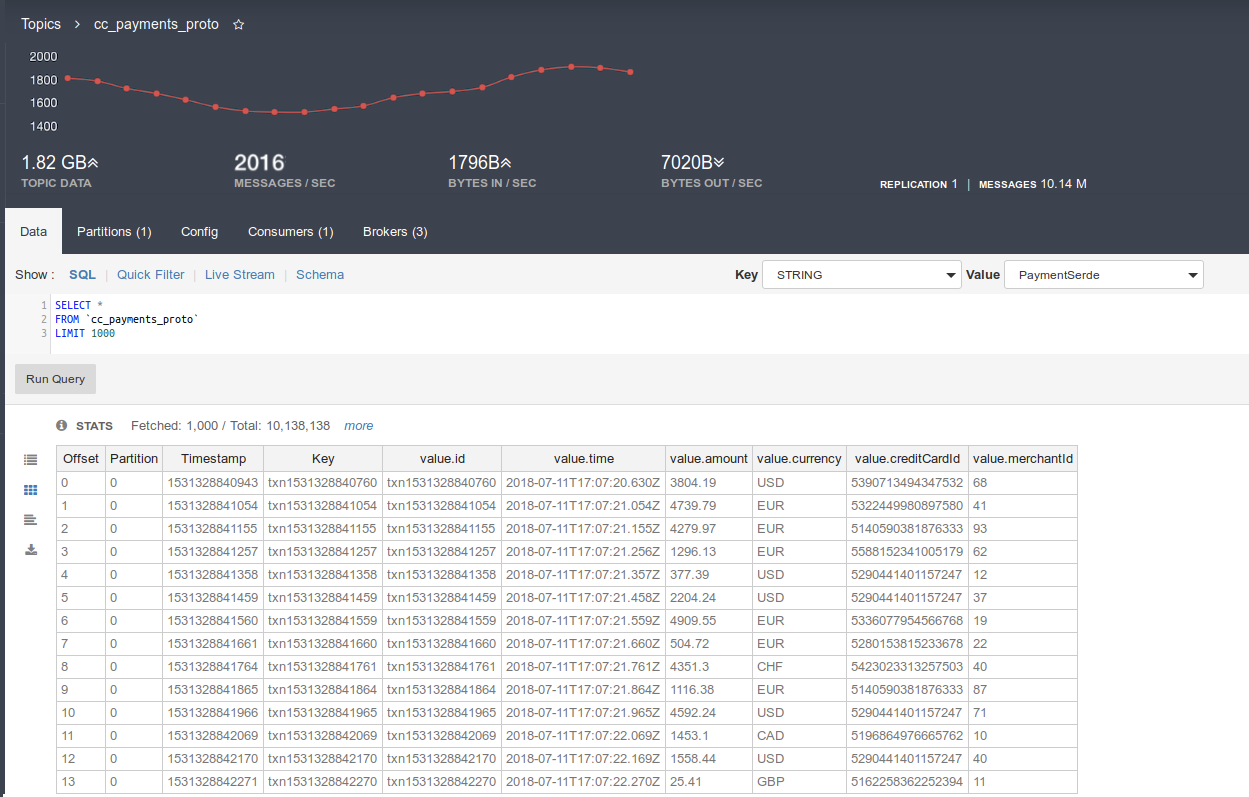
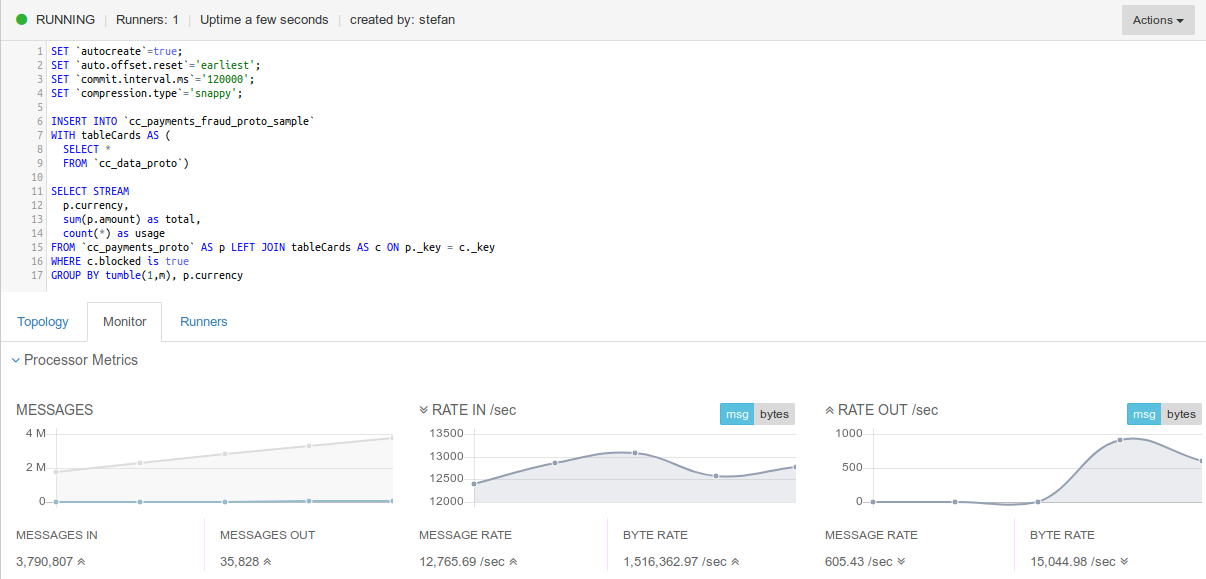
The support for any serialization format extends to both bound and unbound streaming SQL in Lenses, hence joining and aggregating Protobuf data is as simple as working with JSON and Avro. Here is an example of a real time fraud detection (a very simple process) using topics storing data with Protobuf.
Your streaming SQL engine should fit your data structures, not the other way
around. As such, array support was on our road-map from day one. Starting with
this release, you can address arrays and their elements through the typical
array syntax devices[1].temperatures[2]. Of course this functionality
covers all payload types (Avro, JSON, XML, Protobuf, custom), and is supported by
both batch and streaming modes.
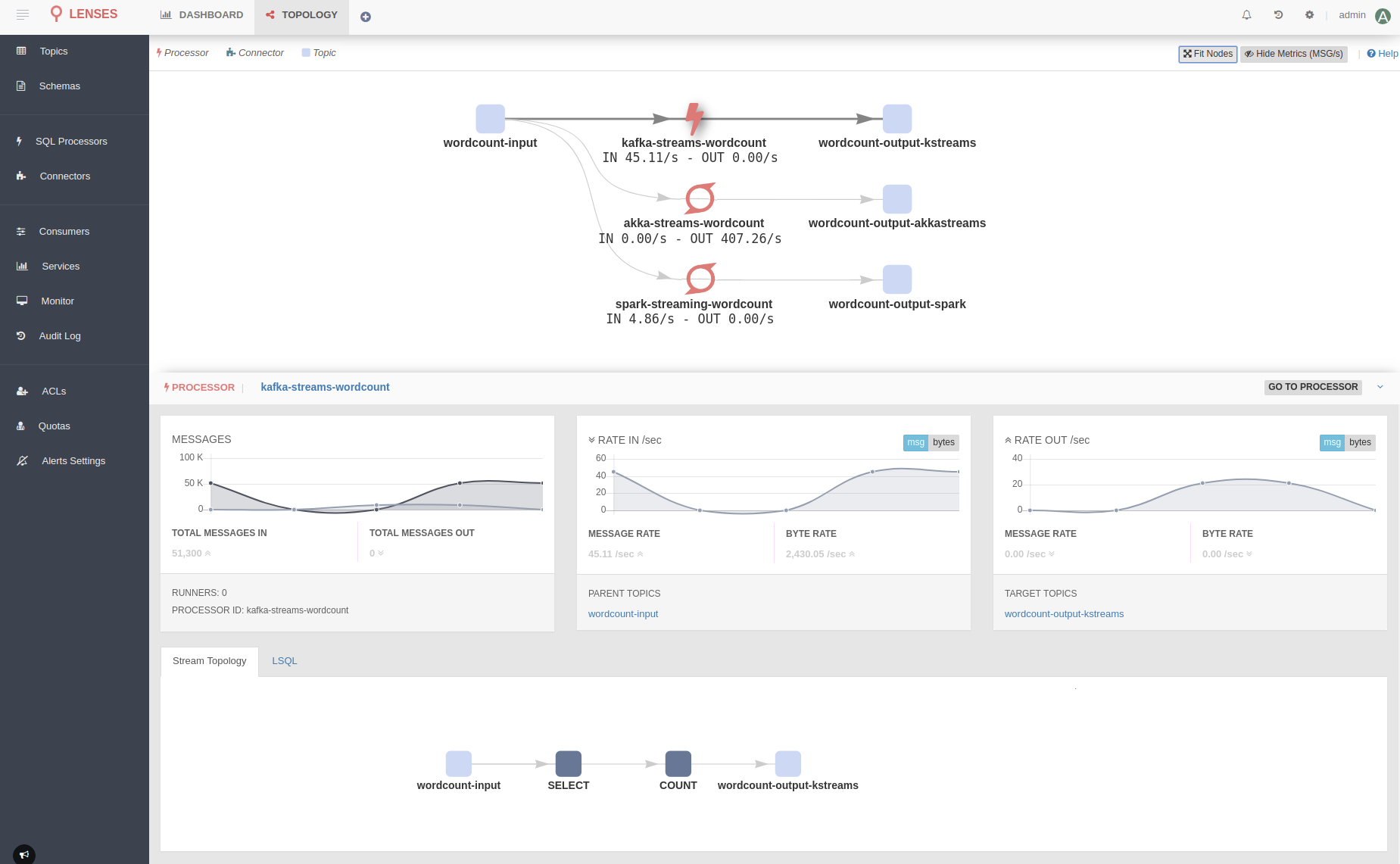
Lenses Topology Graph offers a unique visualization of all your Kafka-native real-time data flows. We trust it will become your go-to place for monitoring all your data streaming pipelines, as it provides a unique high-level view of how your data moves in and out of Kafka.
It is all about giving you control: To make sure things run as expected, to know and understand how your data is moving around and processed within the organization. We want you to be able to answer the following questions without breaking a sweat:
Where is my data flowing from?
Who and how is accessing and manipulating it?
Where is it flowing to?
Until now, Lenses has been answering the question on where your data is originating from, where it is moving to as well as who is processing and how covering both Connectors and Kafka SQL processors. With this new release Lenses fully supports all your micro-services and data processors.
A micro-service can be a simple Kafka consumer or producer, or even have a higher level of complexity using Kafka Streams, Akka Streams or even Apache Spark Streaming to handle real-time stream processing. A topology library supports all data processing frameworks, and examples are available on GitHub.
With the interactive topology providing low latency metrics on each node, Lenses makes sure your real time data flow pipelines are operating in such a manner that meets business requirements. Every team can now take advantage of better control and visibility over the data flow pipelines, irrespective of the underlying technology, leading to a more mature approach to data movement and data operations.
You can find more about monitoring your streaming apps on the topology section of our documentation
We made querying Apache Kafka even easier; Lenses SQL is now context aware. Since the earliest release, Lenses has been continuously identifying the payload types of Kafka topics. An additional set of keywords _ktype and _vtype could be used to explicitly define the payload. This requirement is no more. You can still override the payload types via the _ktype/_vtype if needed, for example when avoiding deserialization to gain higher performance.
Querying Apache Kafka with SQL is as simple as querying a traditional database.
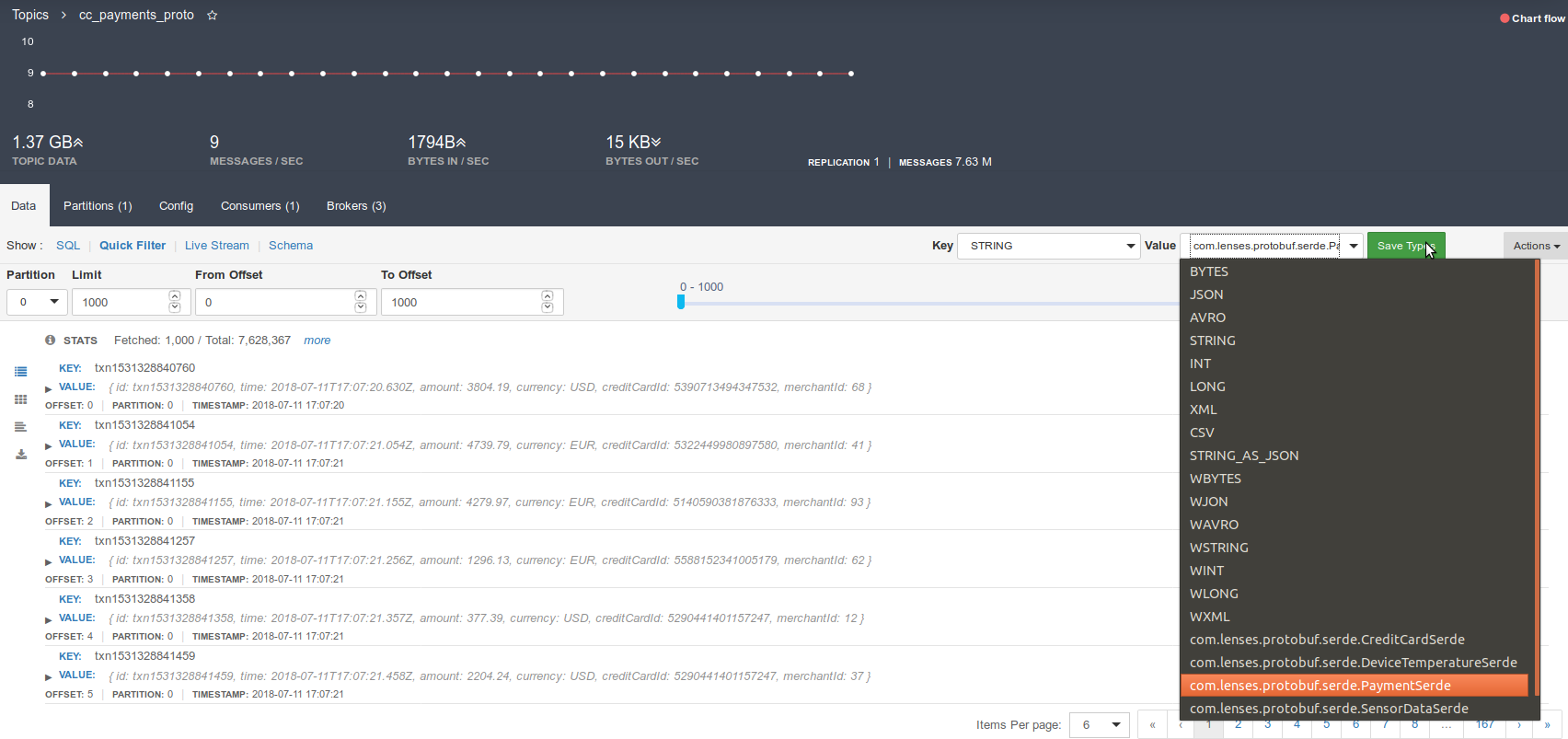
One can always set the topic payload types via the user interface. When there is not enough information to infer the payload type (when there’s no message yet on the topic, for example), or a custom serialization format is used, such as Protobuf, you will have to manually set the payload type once, via the topic page —or our cli tool—, as shown in the image below:
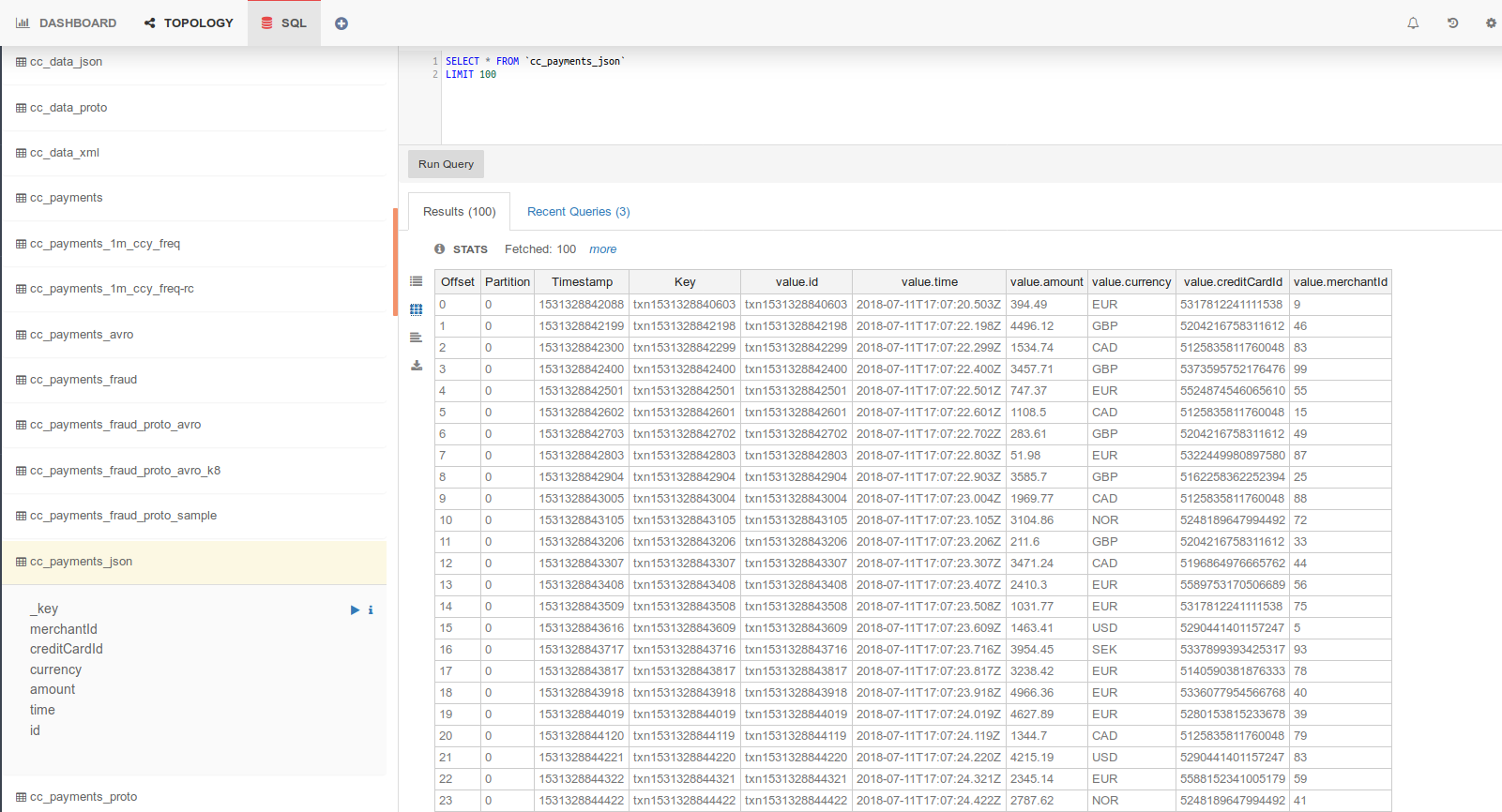
Working with data probably means you write and execute SQL queries every day or even every other minute! Accessing your data with a single click and executing queries is now possible with the new SQL management page.
This new screen gives you access to all available topics, but most importantly their schemas and fields to build queries. Lenses preserves your recent queries, and gives you the results in 3 different modes: tree, grid or raw data. You can also download the computed dataset for further analysis.
Don’t forget that you can hook your queries to your code or your favorite tool with the Lenses SQL JDBC driver or any of our client libraries (go, python, redux).
Enterprise security and Data governance have always been a first class citizen in Lenses. The existing LDAP, Active Directory, SASL/SSL and Kerberos support have been further enhanced with additional enterprise security capabilities.
Kerberos based Single Sign on (SSO) is the latest addition to our supported authentication methods for Lenses.
This release also adds support for Kerberized schema registries (such as the one provided by HortonWorks).
Under the hood, you will find many SQL streaming performance optimizations. The user experience has been significantly enhanced, with both a more responsive UI and usability improvements. You can now retrieve and review all logs from SQL processors that run in Kubernetes. Last but not least a totally revamped Lenses CLI and Python library are now available.
If you are running the Lenses environment for Developers, don’t forget to docker pull to get the latest updates:
docker pull landoop/kafka-lenses-dev:latest
Download Lenses now:
If you want to connect Lenses to your cluster contact us now for a demo and trial!





